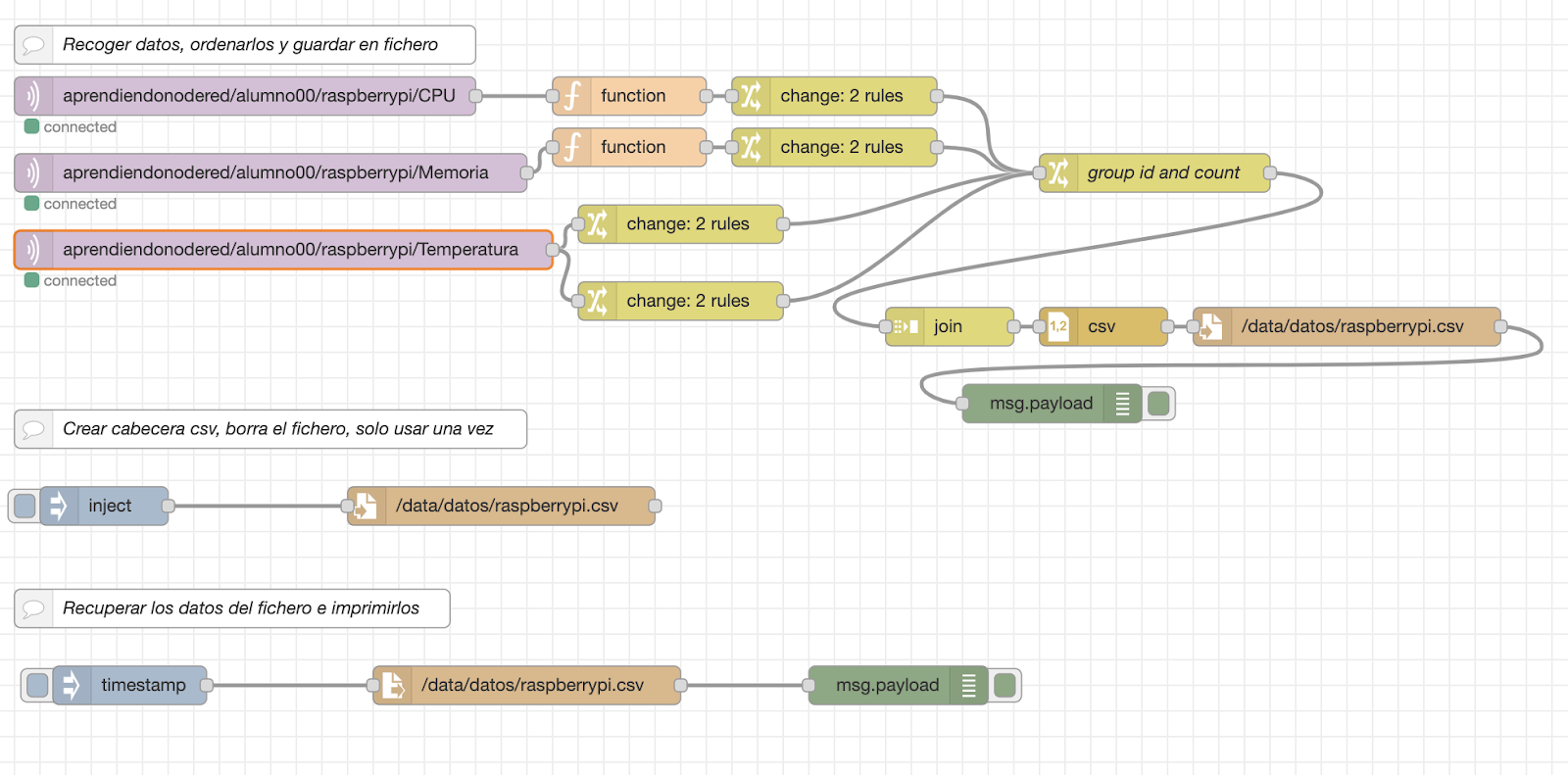
Hacer un CSV con los datos de temperatura, memoria y CPU que manda vuestra Raspberry PI y guardar en un fichero llamado raspberrypi.csv. Añadir también el campo timestamp al fichero csv.
Para ello tomar los datos publicados en MQTT, ordenarlos y prepararlos para que los pase a un nodo join y los ponga en este orden: timestamp,CPU,Memory,Temperature
Para que los ordene de forma automática el nodo join debemos hacer uso de la propiedad parts como hace el nodo split usando:
parts.index – para el orden de los elementos del grupo a unir
parts.id – para indicar que es el mismo grupo
parts.count – para indicar el nº de mensajes del grupo
También crear un flujo con un nodo inject que cree el fichero con la cabecera: “timestamp,CPU,Memory,Temperature” y que además al hacerlo vacíe el fichero existente.
Crear otro flujo con un nodo inject que lee con “file in” el contenido del fichero y lo mande a la pantalla de debug.
Luego con un botón del dashboard hacer la parte de inicializar el fichero (que aparezca una notificación del dashboard para confirmar que se desea inicializar) y con otro botón del dashboard un flujo que lea el fichero y lo mande al nodo chart del dashboard y hacer las gráficas.
Opcionalmente, hacer un tercer botón que mande por email el fichero csv, como fichero adjunto.
Opcionalmente, hacer un flujo que lea los datos del fichero llamado raspberrypi.csv y obtener los datos de media, máxima y mínima de la temperatura, memoria y CPU y mostrar en el dashboard en un nodo texto.
Opcionalmente, hacer un flujo que agrupe los datos en grupos de 100 y sacar los datos de media, máxima y mínima cada 100 valores y guardar en otro fichero llamado raspberrypi_agrupados.csv con los campos: timestamp,CPU_AVG,CPU_MAX,CPU_MIN,Memory_AVG,Memory_MAX,Memory_MIN,Temperature_AVG,Temperature_MAX,Temperature_MIN
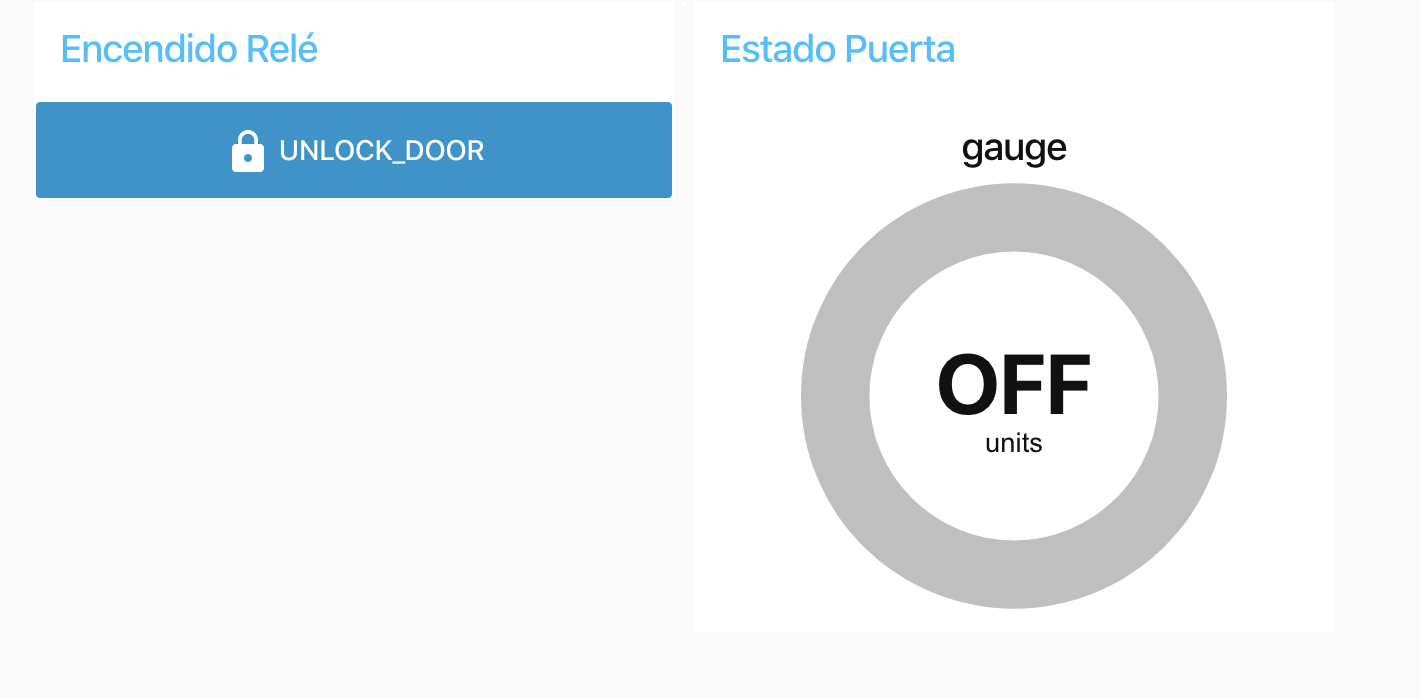
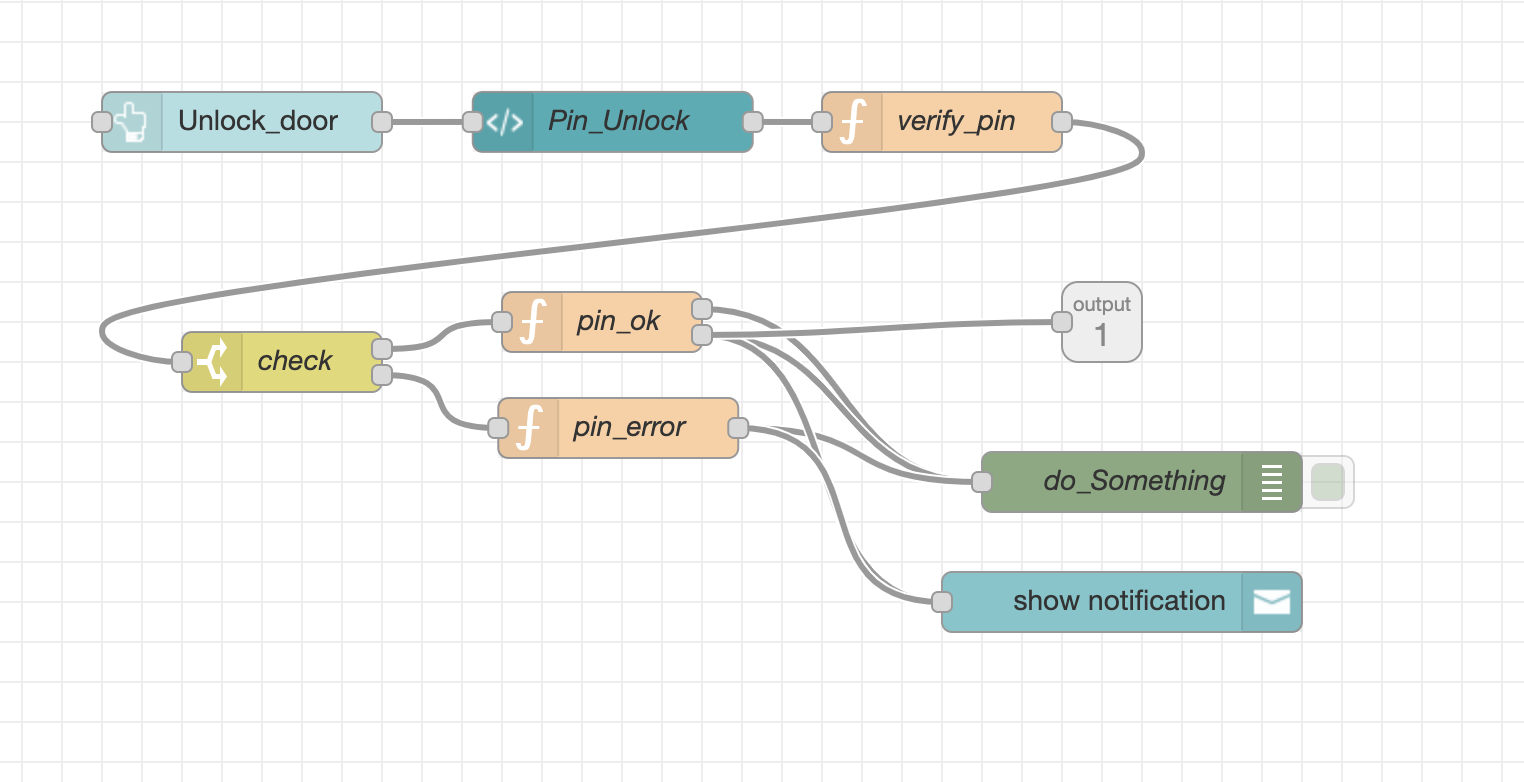
Poner un pin para encender los Reles, de forma que si no hay pin no se puede encender desde el dashboard. Simular una cerradura de forma que al poner el pin correcto se abre y luego a los 5 segundos se cierra.
Mostar en el dashboard el estado de la cerradura.
Crear un tab nuevo en el dashboard llamado pin de seguridad
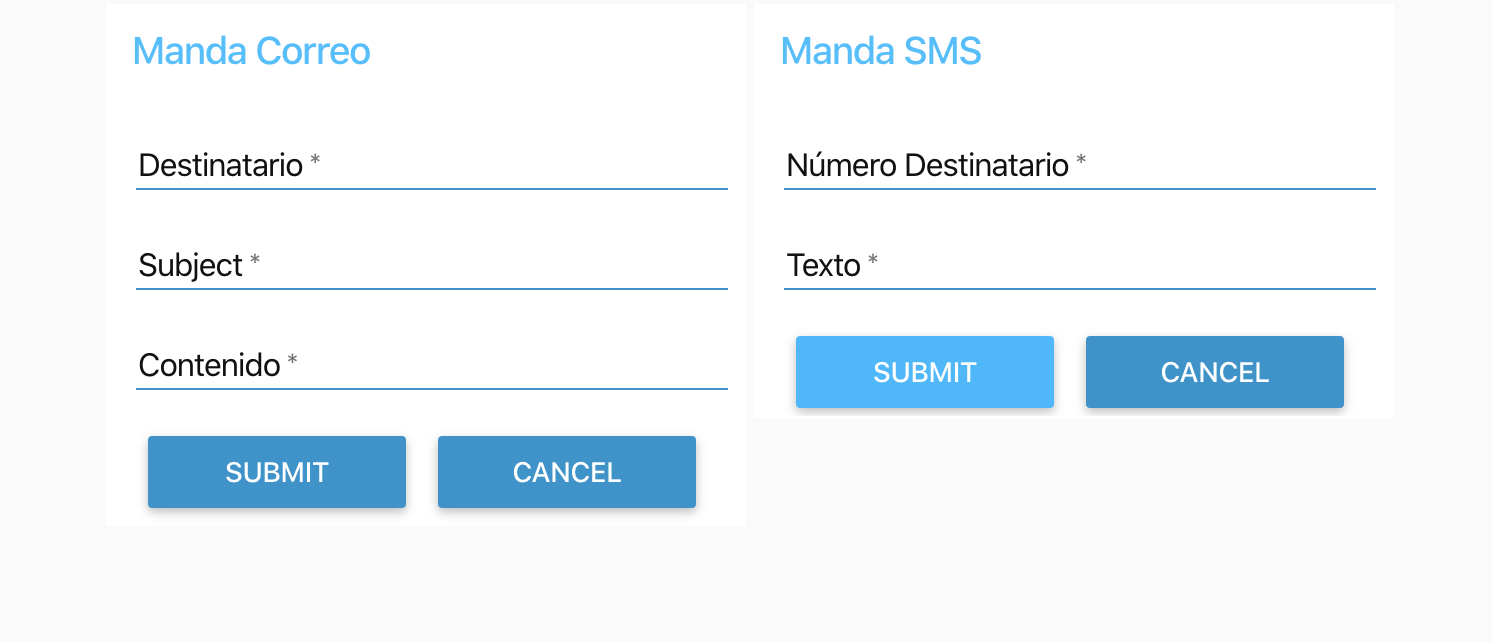
Luego usar esta configuración para enviar un correo y un SMS cuando se pulse el botón de la Raspberry Pi y el relé del nodo remoto 14 esté encendido, viéndolo en un dashboard.
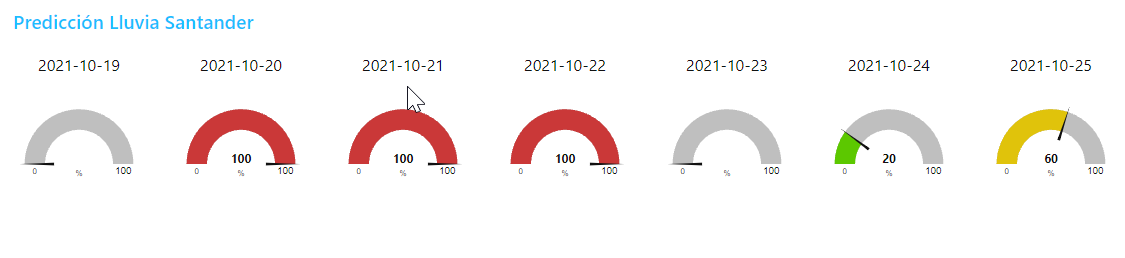
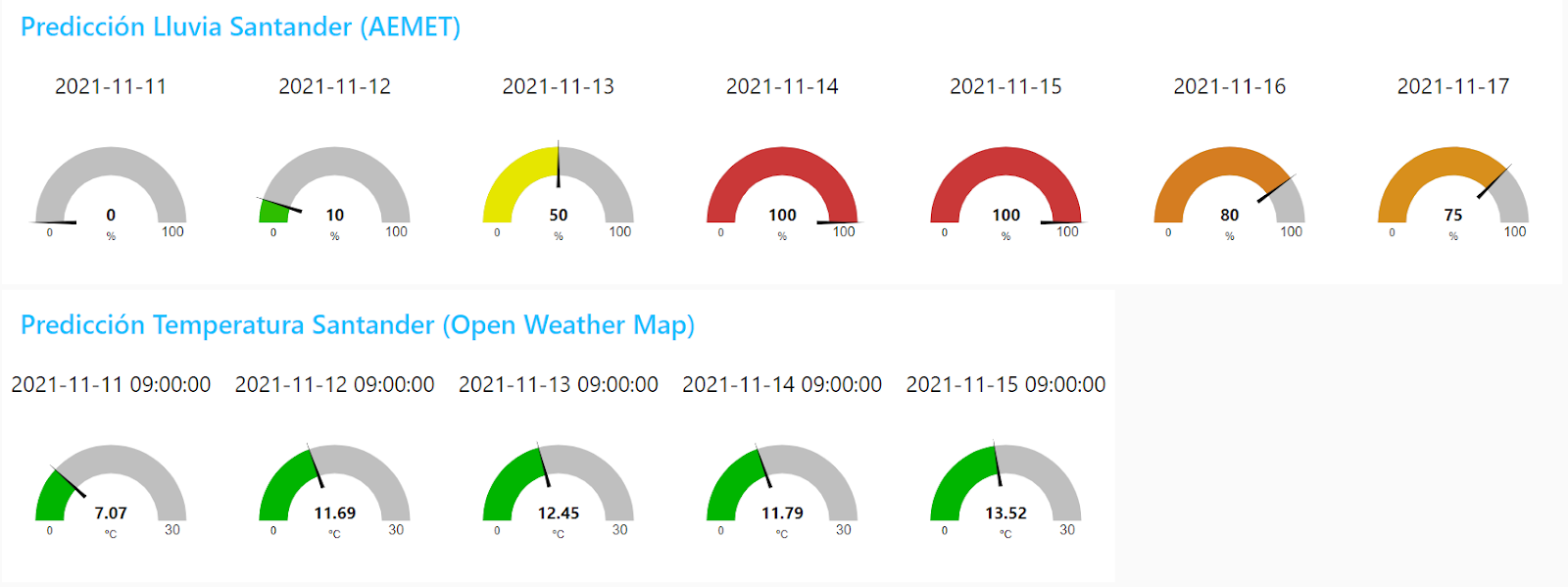
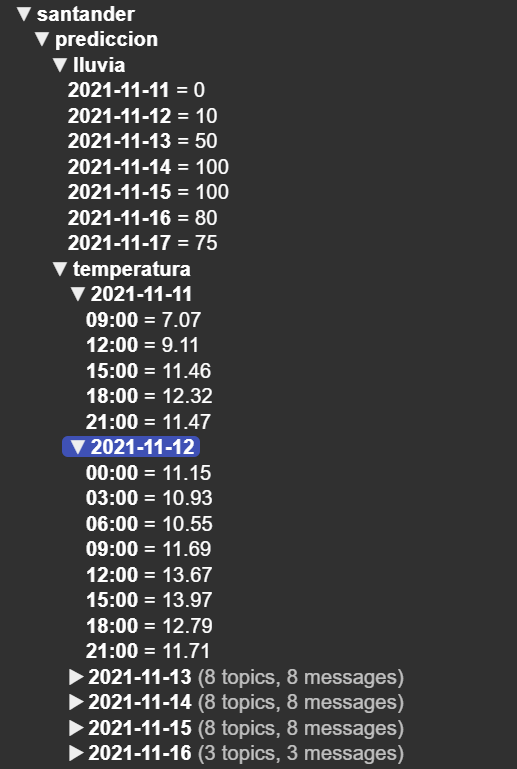
Ejercicio 4 – Predicción de Lluvia con datos AEMET
Hacer un panel de control que muestre la predicción de lluvia de los próximos 7 días de una ciudad usando los datos de AEMET y su API.
Es posible ampliar Node-RED creando nuevos nodos y agregar los nuevos nodos a su paleta. Los nodos se pueden publicar como módulos npm en el repositorio público de npm y agregar a la biblioteca de flujo de Node-RED para que estén disponibles para la comunidad.
Los nodos de Node-RED se empaquetan como módulos y se publican en el repositorio público de npm https://www.npmjs.com/. Una vez publicados en npm, se pueden agregar a la biblioteca de flujo mediante un formulario.
Hay algunos principios generales a seguir al crear nuevos nodos. Estos reflejan el enfoque adoptado por los nodos centrales y ayudan a proporcionar una experiencia de usuario coherente.
Consideraciones Generales
Hay algunos principios generales a seguir al crear nuevos nodos. Estos reflejan el enfoque adoptado por los nodos centrales y ayudan a proporcionar una experiencia de usuario coherente.
Los nodos deben:
Estar bien definidos en su propósito. Un nodo que expone todas las opciones posibles de una API es potencialmente menos útil que un grupo de nodos, cada uno de los cuales tiene un único propósito.
Ser fácil de usar, independientemente de la funcionalidad subyacente. Ocultar la complejidad.
Ser abierto con los tipos de propiedades de mensaje que acepta. Las propiedades de los mensajes pueden ser cadenas, números, valores booleanos, búferes, objetos, matrices o nulos. Un nodo debe hacer lo correcto cuando se enfrenta a cualquiera de estos, evitando ser estricto en el tipo de dato a admitir..
Sea consistente en lo que envían. Los nodos deben documentar las propiedades que agregan a los mensajes y deben ser consistentes y predecibles en su comportamiento.
Detectar errores. Si un nodo arroja un error no detectado, Node-RED detendrá todo el flujo ya que ya no se conoce el estado del sistema. Siempre que sea posible, los nodos deben detectar errores o registrar controladores de errores para cualquier llamada asincrónica que realicen.
Los nodos se crean cuando se implementa un flujo, pueden enviar y recibir algunos mensajes mientras el flujo se está ejecutando y se eliminan cuando se implementa el siguiente flujo.
Consisten en un par de archivos:
un archivo JavaScript que define lo que hace el nodo,
un archivo html que define las propiedades del nodo, el diálogo de edición y el texto de ayuda.
Se usa un archivo package.json para empaquetarlo todo junto como un módulo npm.
Este ejemplo mostrará cómo crear un nodo que convierta las cargas útiles de los mensajes a todos los caracteres en minúsculas. Asegúrese de tener la versión LTS actual de Node.js instalada en su sistema.
Crea un directorio donde desarrollarás tu código. Dentro de ese directorio, cree los siguientes archivos:
package.json – Un archivo json que npm lo usa para empaquetar. Este es el archivo estándar que utilizan los módulos de node.js para describir el contenido
Este es un archivo estándar utilizado por los módulos de Node.js para describir su contenido. Para generar un archivo package.json estándar, puede usar el comando npm init. Esto hará una serie de preguntas para ayudar a crear el contenido inicial del archivo, utilizando valores predeterminados sensibles cuando sea posible. Cuando se le solicite, asígnele el nombre node-red-contrib-example-lower-case.
Una vez generada, debe agregar una sección de Node-RED. Esto le dice al runtime qué archivos de nodo contiene el módulo:
Para obtener más información sobre cómo empaquetar su nodo, incluidos los requisitos de nomenclatura y otras propiedades que deben establecerse antes de publicar su nodo, consulte la guía de empaquetado: https://nodered.org/docs/creating-nodes/packaging
Nota: ¡No publicar este nodo de ejemplo en npm!
lower-case.js – Este archivo normalmente contiene una función javascript que tiene la funcionalidad del módulo de nodo. Esto se llama cuando el tiempo de ejecución carga el nodo al iniciarse.
El nodo está empaquetado como un módulo Node.js. El módulo exporta una función que se llama cuando el tiempo de ejecución carga el nodo en el inicio. La función se llama con un solo argumento, RED, que proporciona al módulo acceso a la API de tiempo de ejecución de Node-RED.
El nodo en sí está definido por una función, LowerCaseNode, que se llama cada vez que se crea una nueva instancia del nodo. Se le pasa un objeto config que contiene las propiedades específicas del nodo establecidas en el editor de flujo. La función llama a la función RED.nodes.createNode para inicializar las características compartidas por todos los nodos.
En este caso, el nodo registra un listener en el evento de entrada que se llama cada vez que llega un mensaje al nodo. Dentro de este listener, cambia la carga útil a minúsculas y luego llama a la función de envío para pasar el mensaje en el flujo.
Finalmente, la función LowerCaseNode se registra con el tiempo de ejecución usando el nombre del nodo “lower-case”.
Si el nodo tiene dependencias de módulos externos, deben incluirse en la sección de dependencias de su archivo package.json.
lower-case.html – Este archivo html contiene la definición de nodo principal que está registrada con el editor. También incluye la plantilla que se muestra cuando se configura el nodo. El contenido de la ayuda y las instrucciones sobre las configuraciones necesarias para el nodo también van aquí.
El archivo HTML de un nodo proporciona lo siguiente:
la definición de nodo principal que está registrada con el editor
la plantilla de edición
el texto de ayuda
En este ejemplo, el nodo tiene una única propiedad editable, name. Si bien no es obligatorio, existe una convención ampliamente utilizada para esta propiedad para ayudar a distinguir entre múltiples instancias de un nodo en un solo flujo.
Una vez creado, vamos a instalarlo. Una vez que haya creado un módulo de nodo básico, puede instalarlo en su runtime de Node-RED. Para probar un módulo de nodo localmente, se puede usar el comando npm install <carpeta>. Esto le permite desarrollar el nodo en un directorio local y vincularlo a una instalación local de node-red durante el desarrollo.
En su directorio de usuario de node-red, normalmente ~/node-red, ejecutar: npm install ../nr_node_development/node-red-contrib-example-lower-case/
Devuelve:
+ red-contrib-example-lower-case@1.0.0
added 1 package from 1 contributor and audited 675 packages in 7.513s
Esto crea un enlace simbólico al directorio del proyecto del módulo de nodo en ~/.node-red/node_modules para que Node-RED detecte el nodo cuando se inicie. Cualquier cambio en el archivo del nodo se puede recoger simplemente reiniciando Node-RED.
Reiniciar Node-RED y comprobar que aparece el nuevo nodo:
Ahora es posible empaquetar un subflujo como un módulo y publicarlo en npm para que se instale en la paleta como cualquier otro nodo
Los subflujos se pueden empaquetar como módulos npm y distribuirse como cualquier otro nodo. Cuando estén instalados, aparecerán en la paleta como nodos regulares. Los usuarios no pueden ver ni modificar el flujo dentro del subflujo.
En esta etapa, la creación del módulo de subflujo es un proceso manual que requiere la edición manual del subflujo JSON. Se proporcionarán herramientas en el futuro para ayudar a automatizar esto.
Cualquier subflujo se puede empaquetar como un módulo. Antes de hacerlo, debe pensar en cómo se utilizará. La siguiente lista de verificación es un recordatorio útil de las cosas a considerar:
Configuración: qué deberá configurar el usuario en el subflujo. Puede definir propiedades de subflujo y qué interfaz de usuario se proporciona para establecer esas propiedades a través del cuadro de diálogo de edición propiedades de subflujo.
Manejo de errores: ¿El subflujo maneja los errores correctamente? Algunos errores pueden tener sentido de manejar dentro del subflujo, algunos pueden necesitar ser pasados fuera del subflujo para permitir que el usuario final los maneje.
Estado: agregar una salida de estado personalizada a su subflujo que puede manejar el nodo «Estado».
Apariencia: dar al subflujo un ícono, color y categoría que tenga sentido para la función que proporciona.
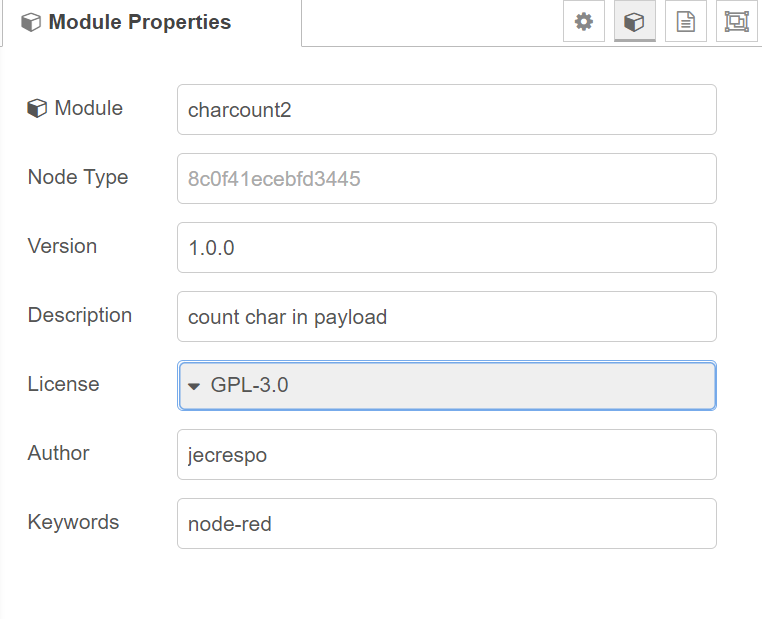
Añadir metadatos al subflujo. El subflujo puede contener metadatos adicionales que se pueden usar para definir el módulo en el que se empaquetará. En el cuadro de diálogo de edición Propiedades del módulo de subflujo, puede establecer las siguientes propiedades:
Módulo: el nombre del paquete npm
Tipo de nodo: se establecerá de forma predeterminada en la propiedad id del subflujo. Es útil proporcionar un mejor valor de tipo. Como ocurre con los tipos de nodos normales, debe ser único para evitar conflictos con otros nodos.
Versión
Descripción
Licencia
Autor
Palabras clave
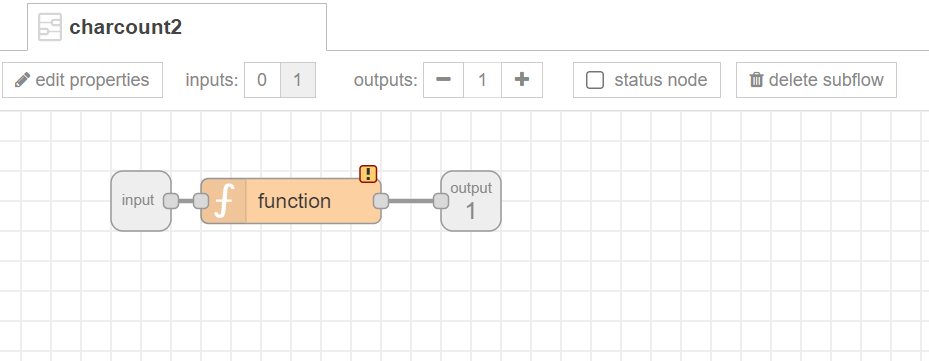
Como ejemplo vamos a crear un nodo basándose en un subflow llamado charcount2 que tiene una entrada y una salida y una función que cuenta caracteres del mensaje entrante:
var newMsg = { "payload": Number(msg.payload.length)};
return newMsg;
Crear el módulo. Este trabajo es manual fuera de Node-RED.
crear un directorio con el nombre que quieras darle al módulo. Para este ejemplo, usaremos node-red-example-charcount2.: mkdir node-red-example-charcount2
User npm init para crear un archivo package.json. Hará una serie de preguntas coincidentes a los valores agregados a los metadatos del subflujo.
Agregar un archivo README.md, ya que todos los módulos buenos deben tener un archivo README.
Crear un contenedor de JavaScript para el módulo. Para este ejemplo, usaremos example.js. Esto lee el contenido de un archivo llamado subflow.json, que crearemos luego, lo analiza y luego lo pasa a la función RED.nodes.registerSubflow.
Añadir el json del subflow. Ahora agregar el subflujo al módulo. Esto requiere una edición cuidadosa del subflujo json.
En el editor Node-RED, agregue una nueva instancia de su subflujo al espacio de trabajo.
Con la instancia seleccionada, exporte el nodo (Ctrl-E o Menú-> Exportar) y pegue el JSON en un editor de texto. Los siguientes pasos serán más fáciles si selecciona la opción «formateado» en la pestaña JSON del cuadro de diálogo Exportar.
El JSON está estructurado como un array de objetos de nodo. La última entrada menos una es la definición de subflujo y la última entrada es la instancia de subflujo que agregó al espacio de trabajo.
Elimine el nodo de instancia de subflujo, la última entrada en la matriz.
Mueva el nodo de definición de subflujo a la parte superior del archivo, encima de la apertura [ de la matriz
Mueva la matriz restante de nodos dentro del nodo de definición de subflujo como una nueva propiedad llamada «flujo».
Asegúrese de ordenar las comas finales entre las entradas movidas.
Actualizar package.json: La tarea final es actualizar el package.json para que Node-RED sepa qué contiene su módulo. Agrega una sección «node-red», con una sección de «nodes» que contiene una entrada para tu archivo .js:
Añadir dependencias: Si el subflujo utiliza nodos no predeterminados, debe asegurarse de que el archivo package.json los enumera como dependencias. Esto asegurará que se instalen junto con su módulo.
Los módulos se enumeran en la sección «dependencies» de nivel superior estándar y una sección «dependencies» en la sección «node-red».
Una vez que haya creado un módulo de nodo básico, puede instalarlo en su runtime de Node-RED. Para probar un módulo de nodo localmente, se puede usar el comando npm install <carpeta>. Esto le permite desarrollar el nodo en un directorio local y vincularlo a una instalación local de node-red durante el desarrollo.
En su directorio de usuario de node-red, normalmente ~/node-red, ejecutar: npm install ../nr_node_development/node-red-example-charcount2/
Esto crea un enlace simbólico al directorio del proyecto del módulo de nodo en ~/.node-red/node_modules para que Node-RED detecte el nodo cuando se inicie. Cualquier cambio en el archivo del nodo se puede recoger simplemente reiniciando Node-RED.
Reiniciar Node-RED y comprobar que aparece el nuevo nodo (subflow y nodo):
Los nodos se pueden empaquetar como módulos y publicar en el repositorio npm. Esto lo hace fácil de instalar junto con las dependencias que puedan tener.
Si desea usar node-red en el nombre del nodo, use node-red-contrib- como prefijo al nombre para dejar en claro que no son mantenidos por el proyecto Node-RED. Alternativamente, se puede usar cualquier nombre que no use node-red como prefijo.
Esta es la típica estructura de directorios. No hay requisitos estrictos sobre la estructura de directorios utilizada dentro del paquete. Si un paquete contiene varios nodos, todos podrían existir en el mismo directorio o cada uno podría colocarse en su propio subdirectorio.
Junto con las entradas habituales, el archivo package.json debe contener una entrada “node-red” que enumere los archivos .js que contienen nodos para que se cargue el tiempo de ejecución. Si tiene varios nodos en un solo archivo, solo tiene que listar el archivo una vez. Si alguno de los nodos tiene dependencias de otros módulos npm, debe incluirse en la propiedad de dependencias.
Para ayudar a que los nodos sean detectables dentro del repositorio npm, el archivo debe incluir node-red en su propiedad de palabras clave. Esto asegurará que el paquete aparezca al buscar por palabra clave.
El archivo README.md debe describir las capacidades del nodo y enumerar los requisitos previos necesarios para que funcione. También puede ser útil incluir cualquier instrucción adicional que no esté incluida en la parte de la pestaña de información del archivo html del nodo, y tal vez incluso un pequeño flujo de ejemplo que demuestre su uso.
A partir de abril de 2020, la biblioteca de flujo Node-RED ya no puede indexar y actualizar automáticamente los nodos publicados en npm con la palabra clave node-red. En cambio, una solicitud de envío debe realizarse manualmente.
Para hacerlo, asegúrese de que se cumplan todas os requisitos de packaging. Para agregar un nuevo nodo a la biblioteca, haga clic en el botón + en la parte superior de la página de la biblioteca https://flows.nodered.org/ y seleccione la opción «nodo». Este botón lo lleva a la página Agregar un nodo. Aquí, la lista de requisitos se repite y describe los pasos para agregarla a la biblioteca.
Para actualizar un nodo existente, puede volver a enviarlo de la misma manera que lo haría para un nuevo nodo o solicitar una actualización desde la página del nodo en la biblioteca de flujo a través del enlace «solicitar actualización». Esto solo es visible para los usuarios registrados. Más información: https://nodered.org/docs/creating-nodes/packaging
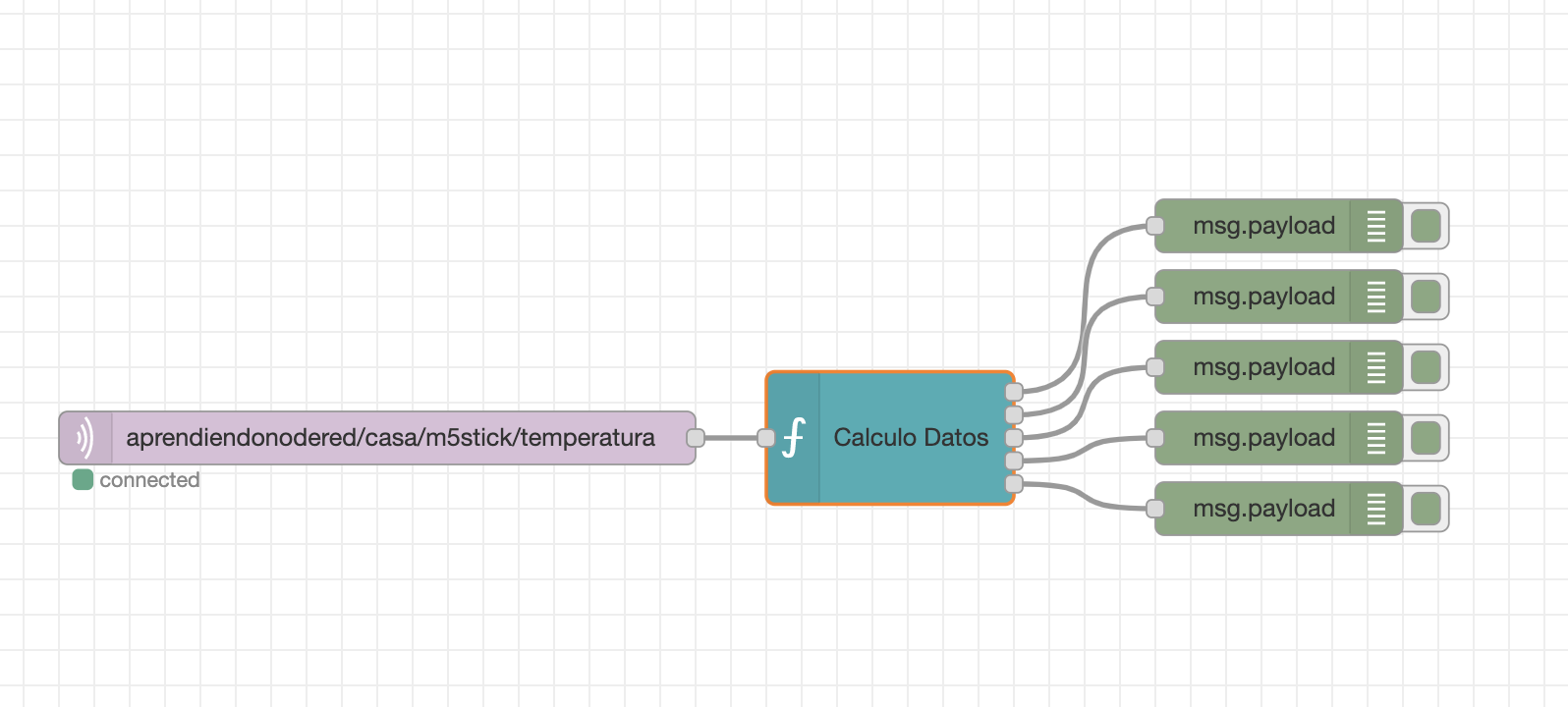
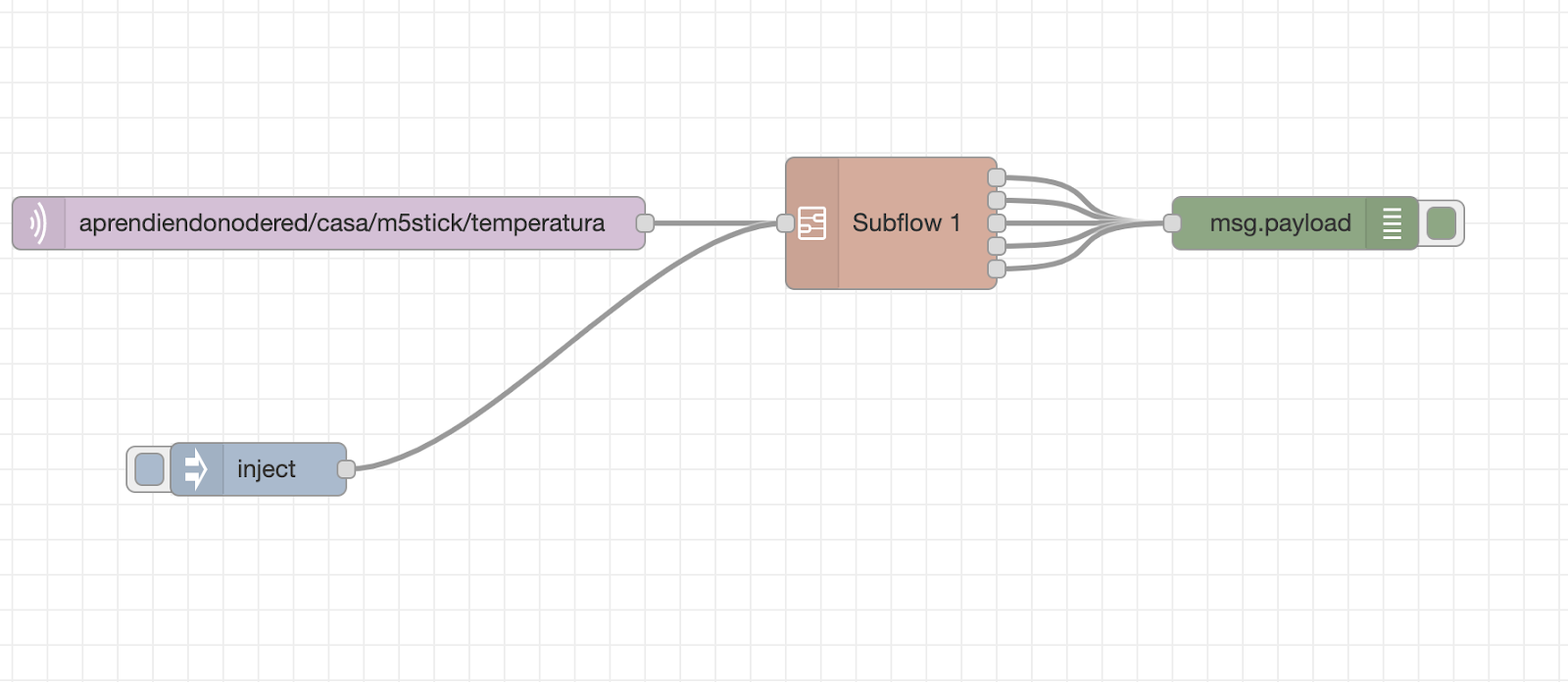
Hacer un subflujo con 5 salidas, que pasándole una variable de entorno con el número de datos a analizar, devuelva la media, máxima y mínima de esos datos por cada salida, una vez retenidos y analizados. En la cuarta salida me devuelva un array de los datos analizados y en la quinta el contador interno.
Personalizar el flujo, añadiendo documentación de lo que hace el subflow y lo que devuelve cada salida.
Hacer una función que guarde los últimos 20 valores en una variable de contexto y una vez tenga los 20, mande la media, máximo y mínimo por tres salidas y en una cuarta mande los 20 mensajes que ha retenido de forma consecutiva. En la quinta salida mandar el dato del contador interno.
Una vez hecho, añadir una funcionalidad para que si recibe un mensaje en la propiedad msg.acumulado, tome ese dato como el número de datos a acumular para hacer el cálculo. Una vez llegue este dato, actualiza el acumulado del contador y en función de lo que lleve acumulado, espera hasta llegar al nuevo dato o si lo ha superado, manda lo que ya tiene.
Por último, encapsular esta función en un subflow para poder reutilizarlo.
JSONata es un lenguaje de consulta y transformación de objetos JSON
Las estructuras de datos son uno de los elementos más importantes de cualquier lenguaje de programación. Nos permite estructurar los datos de manera consistente y realizar operaciones que requieren algunos patrones. Sin un patrón, es difícil para cualquier desarrollador encontrar una forma eficiente de extraer o manipular los datos. JSON es un formato muy conocido que la mayoría de nosotros usamos todos los días. Al trabajar con él, hay operaciones que hacemos habitualmente, como consultar, filtrar, ordenar, agrupar y otras.
JSONata es un lenguaje ligero de consulta y transformación para datos JSON. Inspirado en la semántica de ‘location path’ de XPath 3.1, permite expresar consultas sofisticadas en una notación compacta e intuitiva. Se proporciona un rico complemento de operadores y funciones incorporados para manipular y combinar datos extraídos, y los resultados de las consultas se pueden formatear en cualquier estructura de salida JSON utilizando un objeto JSON familiar y una sintaxis de array. Junto con la posibilidad de crear funciones definidas por el usuario, se pueden crear expresiones avanzadas para abordar cualquier tarea de transformación y consulta JSON.
Para admitir la extracción de valores de una estructura JSON, se define una sintaxis de ruta de ubicación. Al igual que XPath, esto seleccionará todos los valores posibles en el documento que coincidan con la ruta de ubicación especificada. Las dos construcciones estructurales de JSON son objetos y arrays.
Un objeto JSON es una matriz asociativa. La sintaxis de la ruta de ubicación para navegar en una estructura profundamente anidada de objetos JSON comprende los nombres de campo separados por un punto ‘.’ delimitadores. La expresión devuelve el valor JSON al que se hace referencia después de navegar al último paso en la ruta de ubicación. Si durante la navegación de la ruta de ubicación, no se encuentra un campo, la expresión no devuelve nada (representado por Javascript undefined). No se producen errores como resultado de datos no existentes en el documento de entrada.
Los arrays JSON se utilizan cuando se requiere una colección ordenada de valores. Cada valor de la matriz está asociado con un índice (posición) en lugar de un nombre, por lo que para abordar valores individuales en una matriz, se requiere sintaxis adicional para especificar el índice. Esto se hace usando corchetes después del nombre de campo de la matriz. Si los corchetes contienen un número o una expresión que se evalúa como un número, entonces el número representa el índice del valor a seleccionar. Los índices tienen un desplazamiento cero, es decir, el primer valor de una matriz arr es arr [0]. Si el número no es un número entero, entonces se redondea a un número entero. Si la expresión entre corchetes no es numérica o es una expresión que no se evalúa como un número, entonces se trata como un predicado.
Los índices negativos cuentan desde el final de la matriz, por ejemplo, arr [-1] seleccionará el último valor, arr [-2] el penúltimo, etc. Si se especifica un índice que excede el tamaño de la matriz, entonces no se selecciona nada.
Si no se especifica ningún índice para una matriz (es decir, no hay corchetes después de la referencia del campo), se selecciona toda la matriz. Si la matriz contiene objetos y la ruta de ubicación selecciona campos dentro de estos objetos, se consultará cada objeto dentro de la matriz para su selección.
En cualquier paso de una ruta de ubicación, los elementos seleccionados se pueden filtrar utilizando un predicado – [expr] donde expr se evalúa como un valor booleano. Cada elemento de la selección se compara con la expresión, si se evalúa como verdadero, entonces el elemento se mantiene; si es falso, se elimina de la selección. La expresión se evalúa en relación con el elemento actual (contexto) que se está probando, por lo que si la expresión de predicado realiza la navegación, entonces es relativa a este elemento de contexto.
Uso de * en lugar del nombre del campo para seleccionar todos los campos de un objeto.
El comodín descendiente ** en lugar de * atravesará todos los descendientes (comodín de varios niveles).
Al procesar el valor de retorno de una expresión JSONata, podría ser conveniente tener los resultados en un formato coherente, independientemente de cuántos valores coinciden, es decir, forzar a que devuelva un array de valores. La expresión se puede modificar para que devuelva un array incluso si solo se coincide con un valor único. Esto se hace agregando corchetes vacíos [] a un paso dentro de la ruta de ubicación.
Funciones y Expresiones
Strings
Las expresiones de ruta que apuntan a un valor de cadena (string) devolverán ese valor.
Los literales de strings también se pueden crear encerrando la secuencia de caracteres entre comillas. Se pueden utilizar comillas dobles » o comillas simples ‘, siempre que se utilice el mismo tipo de comillas para el inicio y el final del literal de cadena. Los caracteres de comillas simples se pueden incluir dentro de una cadena de comillas dobles y viceversa sin escapar. Caracteres dentro del string se puede escapar utilizando el mismo formato que las cadenas JSON.
Las cadenas se pueden combinar utilizando el operador de concatenación &. Este operador unirá las dos cadenas devueltas por las expresiones a cada lado. Este es el único operador que intentará forzar sus operandos al tipo esperado (cadena).
Numéricos
Los literales numéricos también se pueden crear utilizando la misma sintaxis que los números JSON. Los números se pueden combinar utilizando los operadores matemáticos habituales para producir un número resultante. Operadores admitidos:
+ suma
– resta
* multiplicación
/ división
% resto (módulo)
$number pasa a número el dato y poder operar en JSONata
Comparación
Se utiliza a menudo en predicados, para comparar dos valores. Devuelve un valor booleano verdadero o falso. Operadores admitidos:
= igual
! = no es igual
< menor que
<= menor o igual que
> mayor que
> = mayor o igual que
in valor está contenido en una matriz
Booleanos
Se utiliza para combinar resultados booleanos, a menudo para admitir expresiones de predicado más sofisticadas. Operadores admitidos:
and
or
Ejemplo: $[data.age > 16 and data.age < 20]
Tenga en cuenta que not se admite como función, no como operador.
Mostrar en el dashboard en un mismo grupo 3 widgets text donde cada segundo actualice el timestamp (epoch time), la fecha usando el nodo node-red-contrib-date y el día y hora en formato, usando el nodo moment para transformarlo.
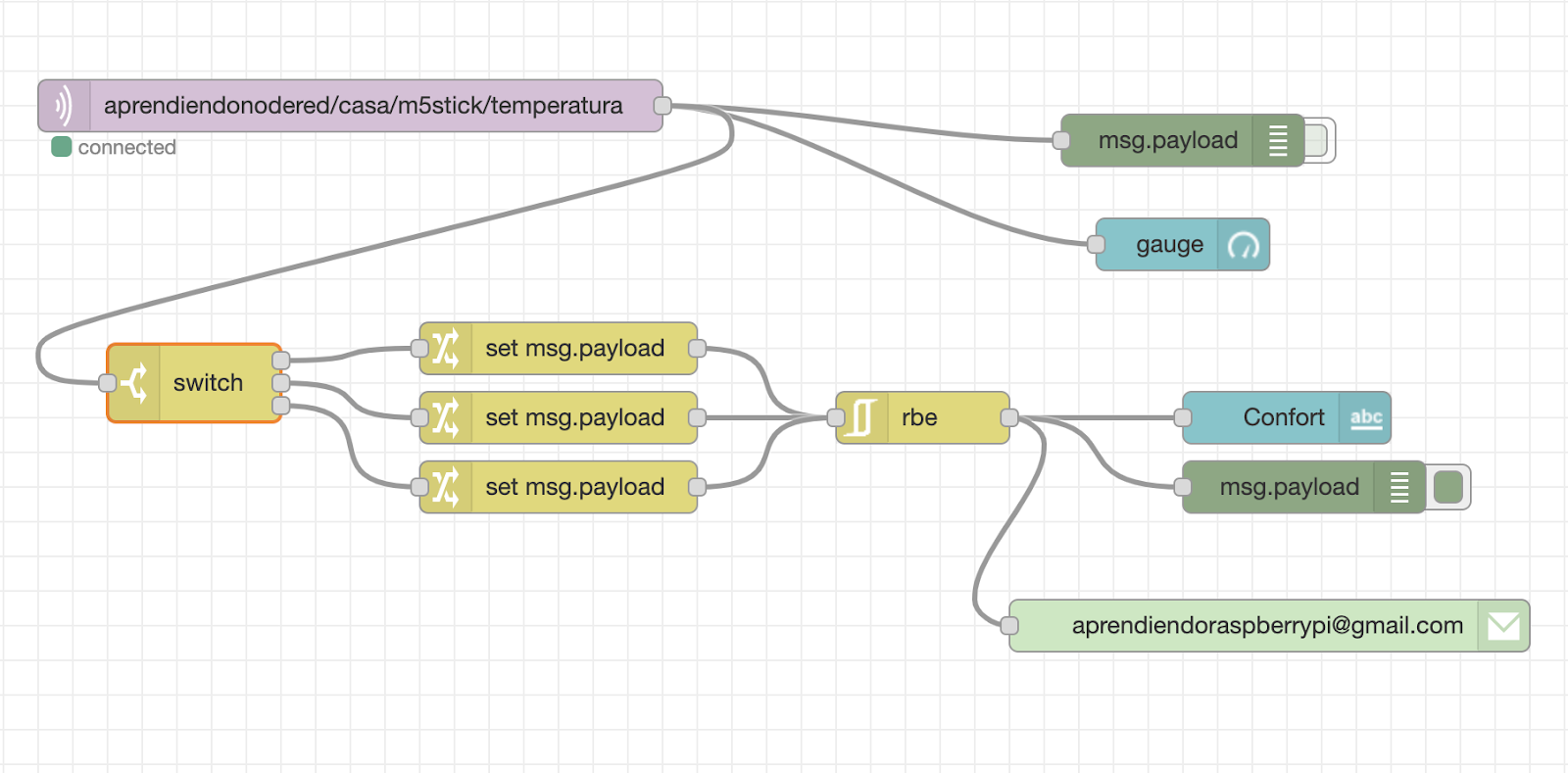
Leer el dato de la temperatura publicado en MQTT y hacer que cuando la temperatura esté fuera de un rango entre 18 y 22 grados, ponga el estado de confort en un elemento del dashboard y mande un email.
En este caso uso un nodo change donde borro payload y pongo las propiedades msg.ui_control.seg1 y msg.ui_control.seg2 a los valores almacenados en las variables de contexto.
Por último no dejar que el valor MIN sea mayor que MAX, ni que MAX sea menor que min en el dashboard, para ello controlar el valor de MIN y MAX al cambiar con un nodo switch y tomar la decisión a hacer.













{kind=link}