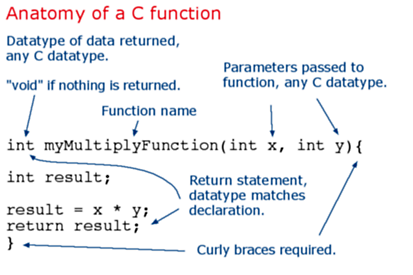
El nodo Function te permite ejecutar cualquier código JavaScript contra el mensaje. Esto te da una completa flexibilidad en lo que haces con el mensaje, pero requiere familiaridad con JavaScript y es innecesario para muchos casos simples.
Muchas veces existen nodos ya hechos para alguna función que deseemos hacer, si eres novato, antes de hacer una función busca en https://flows.nodered.org/ si hay algún nodo o flujo que lo haga.
El nodo función es un bloque de funciones de JavaScript que se ejecuta contra los mensajes que recibe el nodo. Los mensajes se pasan como un objeto JavaScript llamado msg.
Por convención, tendrá una propiedad msg.payload que contiene el cuerpo del mensaje, además de otras propiedades opcionales como msg.topic.
Se espera que la función devuelva un objeto de mensaje (o varios objetos de mensaje), pero puede optar por no devolver nada para detener un flujo.

La pestaña Setup contiene código que se ejecutará siempre que se inicie el nodo. La pestaña Close contiene código que se ejecutará cuando se detenga el nodo.

Desde la versión 1.1.0, el nodo Función proporciona una pestaña Configuración donde puede proporcionar código que se ejecutará siempre que se inicie el nodo. Esto se puede utilizar para configurar cualquier estado que requiera el nodo Función.
Por ejemplo, puede inicializar valores en contexto local que usará la función principal:
if (context.get("counter") === undefined) {
context.set("counter", 0)
} Tenga en cuenta que cada fragmento de código está en un ámbito separado; no puede declarar variables en uno y acceder a ellas en los demás. Necesitas usar el contexto para pasar cosas entre ellos.
La función de Setup puede devolver una Promise (promesa) si necesita completar un trabajo asincrónico antes de que la función principal pueda comenzar a procesar mensajes. Cualquier mensaje que llegue antes de que se complete la función de configuración se pondrá en cola y se manejará cuando esté listo.
Si usa código callback asíncrono en sus funciones, es posible que deba limpiar las solicitudes pendientes o cerrar cualquier conexión, cuando el nodo sea re-deployed. Puede hacer esto de dos formas diferentes.
O agregando un controlador de eventos en caso de close:
node.on('close', function() {
// tidy up any async code here - shutdown connections and so on.
}); O, desde Node-RED 1.1.0, puede agregar código a la pestaña Close en el cuadro de diálogo de edición del nodo.
Las pestañas Setup y Close se ejecutan cuando se hace un deploy o al reiniciar Node-RED.
Mas información sobre escribir funciones en Node-RED:
- https://nodered.org/docs/user-guide/writing-functions
- http://www.steves-internet-guide.com/node-red-functions/
- https://notenoughtech.com/home-automation/nodered-for-beginners-6/
Pros y contras de usar funciones en lugar de nodos: https://discourse.nodered.org/t/pros-and-cons-about-using-custom-functions-vs-the-basic-set-of-nodes/2959
Otro nodo alternativo con procesos hijos es func-exec: https://flows.nodered.org/node/node-red-contrib-func-exec
Vídeo: https://www.youtube.com/watch?v=8XL3Zq1HjCo
Escribir una Función
El código dentro del nodo Función representa el cuerpo de la función. La función más simple simplemente devuelve el mensaje exactamente como está: return msg;
Si la función devuelve un valor nulo, no se transmite ningún mensaje y el flujo finaliza.
La función siempre debe devolver un objeto msg. Devolver un número o una cadena resultará en un error.
El objeto del mensaje devuelto no necesita ser el mismo objeto que se pasó; la función puede construir un objeto completamente nuevo antes de devolverlo. La construcción de un nuevo objeto de mensaje perderá todas las propiedades del mensaje recibido. Esto interrumpirá algunos flujos, por ejemplo, el flujo de entrada/respuesta HTTP requiere que las propiedades msg.req y msg.res se conserven de un extremo a otro. En general, los nodos de función deben devolver el objeto de mensaje que se les pasó después de haber realizado cambios en sus propiedades.
Función que devuelve un nuevo mensaje eliminando las propiedades del mensaje original:
var newMsg = { payload: msg.payload.length };
return newMsg; Ejemplo, crear una función que pase el payload y el topic a mayúsculas:
var payload=msg.payload; //get payload
msg.payload=payload.toUpperCase(); //convert to uppercase
var topic=msg.topic; //get topic
msg.topic=topic.toUpperCase();//convert to uppercase
return msg; Enviando mensajes
La función puede devolver los mensajes que quiere pasar a los siguientes nodos del flujo con return o puede llamar a node.send (mensajes).
Puede devolver o enviar:
- un objeto de mensaje único: se pasa a los nodos conectados a la primera salida
- una matriz de objetos de mensaje: se pasa a los nodos conectados a las salidas correspondientes (múltiples salidas)
Si algún elemento de la matriz es en sí mismo una matriz de mensajes, se envían varios mensajes a la salida correspondiente.
Si se devuelve un valor nulo, ya sea por sí mismo o como un elemento de la matriz, no se transmite ningún mensaje.
Múltiples Salidas
El diálogo de edición de funciones permite cambiar el número de salidas. Si hay más de una salida, la función puede devolver una matriz de mensajes para enviar a las salidas.
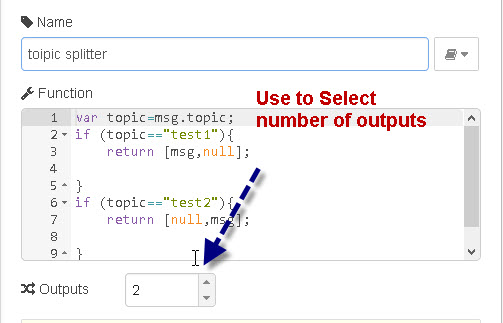
Esto facilita escribir una función que envíe el mensaje a diferentes salidas dependiendo de alguna condición. Por ejemplo, esta función enviaría cualquier cosa sobre el tema banana a la segunda salida en lugar de a la primera:
if (msg.topic === "banana") {
return [ null, msg ];
} else {
return [ msg, null ];
} 
El siguiente ejemplo pasa el mensaje original tal cual en la primera salida y un mensaje que contiene la longitud de la carga útil se pasa a la segunda salida:
var newMsg = { payload: msg.payload.length };
return [msg, newMsg]; Ejemplo. Usamos dos nodos inject para inyectar un mensaje sobre dos temas diferentes en un nodo de función con dos salidas. La función envía el mensaje a la salida según el nombre del tema. El tema test1 va a output1 y test2 va a output2.

Código:
var topic=msg.topic;
if (topic=="test1"){
return [msg,null];
}
if (topic=="test2"){
return [null,msg];
} Múltiples Mensajes
Una función puede devolver varios mensajes en una salida al devolver una matriz de mensajes dentro de la matriz devuelta. Cuando se devuelven varios mensajes para una salida, los nodos posteriores recibirán los mensajes uno a uno en el orden en que se devolvieron.
En el siguiente ejemplo, msg1, msg2, msg3 se enviarán a la primera salida y msg4 se enviará a la segunda salida.
var msg1 = { payload:"first out of output 1" };
var msg2 = { payload:"second out of output 1" };
var msg3 = { payload:"third out of output 1" };
var msg4 = { payload:"only message from output 2" };
return [ [ msg1, msg2, msg3 ], msg4 ]; El siguiente ejemplo divide la carga útil recibida en palabras individuales y devuelve un mensaje para cada una de las palabras.
var outputMsgs = [];
var words = msg.payload.split(" ");
for (var w in words) {
outputMsgs.push({payload:words[w]});
}
return [outputMsgs]; Ejemplo. Usar un nodo inject para inyectar una cadena de prueba en el nodo de función. El nodo de función toma la cadena, pero en lugar de enviar 1 mensaje, tiene un bucle for que crea 3 mensajes y los coloca en un array.
Código:
var m_out=[]; //array for message objects
var message=msg.payload;
for (i=0;i<3;i++){
message=message+i; //add count to message
var newmsg={payload:message,topic:msg.topic}
m_out.push(newmsg);
}
return [m_out]; Enviar mensajes de forma asincrónica
Si la función necesita realizar una acción asincrónica antes de enviar un mensaje, no puede devolver el mensaje al final de la función con return.
En su lugar, debe hacer uso de la función node.send(), pasando los mensajes que se enviarán.
Por ejemplo:
doSomeAsyncWork(msg, function(result) {
msg.payload = result;
node.send(msg);
});
return; Esto es útil, por ejemplo, al recorrer una matriz u objeto y enviar datos a medida que se leen. Por ejemplo:
count=0;
for(var i=0;i<10;i++)
{
msg.payload=count;
node.send(msg)
count+=1;
} Ejemplo: ver como al mandar send, los mensajes se procesan de forma simultánea al ser asíncrono:
for(var i=0;i<10;i++) {
msg.payload=i;
await new Promise(r => setTimeout(r, 1000)); //sleep(1000)
node.send(msg);
} Desde la versión Node-RED 1.0, el nodo Función clonará cada objeto de mensaje que pase a node.send para garantizar que no haya modificaciones no intencionales de los objetos de mensaje que se reutilicen en la función.
La función puede solicitar al tiempo de ejecución (runtime) que no clone el primer mensaje pasado a node.send pasando falso como segundo argumento de la función. Haría esto si el mensaje contiene algo que de otra manera no se puede clonar, o por razones de rendimiento para minimizar la sobrecarga de enviar mensajes: node.send(msg,false);
Si un nodo Función realiza un trabajo asincrónico con un mensaje, el tiempo de ejecución no sabrá automáticamente cuándo ha terminado de manejar el mensaje.
Para ayudarlo a hacerlo, el nodo Función debe llamar a node.done() en el momento apropiado. Esto permitirá que el tiempo de ejecución rastree correctamente los mensajes a través del sistema.
doSomeAsyncWork(msg, function(result) {
msg.payload = result;
node.send(msg);
node.done();
});
return; Registro y manejo de errores
Para registrar cualquier información o reportar un error, las siguientes funciones están disponibles:
- node.log(«Log message»)
- node.warn(«Warning»)
- node.error(«Error»)
Los mensajes de warn y error también se envían a la pestaña de debug del editor de flujo.
Para un registro más fino, también están disponibles node.trace() y node.debug(). Si no hay ningún logger configurado para capturar esos niveles, no se verán.
Si la función encuentra un error que debería detener el flujo actual, no debería devolver nada. El nodo Catch se puede utilizar para manejar errores. Para invocar un nodo Catch, pase msg como segundo argumento a node.error: node.error(«Error», msg);
Acceder a la información del nodo
En el bloque de funciones, se puede hacer referencia a la identificación y el nombre del nodo mediante las siguientes propiedades:
- node.id – id del nodo
- node.name – nombre del nodo
Uso de variables de entorno
Se puede acceder a las variables de entorno usando: env.get («MY_ENV_VAR»).
Variables de entorno: https://nodered.org/docs/user-guide/environment-variables
Almacenamiento de datos
Aparte del objeto msg, la función también puede almacenar datos en el almacén de contexto: https://nodered.org/docs/user-guide/context
En el nodo Función hay tres variables predefinidas que se pueden usar para acceder al contexto:
- context: el contexto local del nodo
- flow: el contexto del alcance del flujo
- global: el contexto de alcance global
Estas variables predefinidas son una característica del nodo Función y no se usan en la creación de nodos.
Hay dos modos de acceder al contexto; ya sea sincrónico o asincrónico. Los almacenes de contexto integrados proporcionan ambos modos. Es posible que algunos almacenes solo den acceso asincrónico y arrojará un error si se accede a ellas de manera sincrónica.
Para obtener un valor del contexto: var myCount = flow.get(«count»);
Para establecer un valor: flow.set(«count», 123);
El siguiente ejemplo mantiene un recuento de cuántas veces se ha ejecutado la función:
// initialise the counter to 0 if it doesn't exist already
var count = context.get('count')||0;
count += 1;
// store the value back
context.set('count',count);
// make it part of the outgoing msg object
msg.count = count;
return msg; get/set multiples valores:
var values = flow.get(["count", "colour", "temperature"]);
// values[0] is the 'count' value
// values[1] is the 'colour' value
// values[2] is the 'temperature' value
flow.set(["count", "colour", "temperature"], [123, "red", "12.5"]); El contexto global se puede rellenar previamente con objetos cuando se inicia Node-RED. Esto se define en el archivo principal settings.js bajo la propiedad functionGlobalContext.
Esto se puede utilizar para cargar módulos adicionales dentro del nodo Función: https://nodered.org/docs/user-guide/writing-functions#loading-additional-modules
Acceso al contexto asincrónico
Si el almacén de contexto requiere acceso asincrónico, las funciones get y set requieren un parámetro de devolución de llamada adicional.
// Get single value
flow.get("count", function(err, myCount) { ... });
// Get multiple values
flow.get(["count", "colour"], function(err, count, colour) { ... })
// Set single value
flow.set("count", 123, function(err) { ... })
// Set multiple values
flow.set(["count", "colour", [123, "red"], function(err) { ... }) El primer argumento pasado a la callback, err, solo se establece si ocurrió un error al acceder al contexto.
La versión asincrónica del ejemplo de recuento se convierte en:
context.get('count', function(err, count) {
if (err) {
node.error(err, msg);
} else {
// initialise the counter to 0 if it doesn't exist already
count = count || 0;
count += 1;
// store the value back
context.set('count',count, function(err) {
if (err) {
node.error(err, msg);
} else {
// make it part of the outgoing msg object
msg.count = count;
// send the message
node.send(msg);
}
});
}
}); Múltiples Almacenes de Contexto
Es posible configurar múltiples almacenes de contexto. Por ejemplo, se podría utilizar un almacén basado en memoria y en archivos.
Las funciones de contexto get/set aceptan un parámetro opcional para identificar el almacén a utilizar.
// Get value - sync
var myCount = flow.get("count", storeName);
// Get value - async
flow.get("count", storeName, function(err, myCount) { ... });
// Set value - sync
flow.set("count", 123, storeName);
// Set value - async
flow.set("count", 123, storeName, function(err) { ... }) Añadir Estado
El nodo de función también puede proporcionar su propia decoración de estado de la misma forma que otros nodos. Para establecer el estado, llame a la función node.status. Por ejemplo:
node.status({fill:"red",shape:"ring",text:"disconnected"});
node.status({fill:"green",shape:"dot",text:"connected"});
node.status({text:"Just text status"});
node.status({}); // to clear the status Para los parámetros aceptados en el estado ver https://nodered.org/docs/creating-nodes/status
- fill – red, green, yellow, blue or grey
- shape – Ring or Dot

Las actualizaciones de estado también pueden ser capturadas por el nodo Estado.
Carga de módulos adicionales
Si se necesita usar un módulos de node.js es necesario activarlos previamente. Los módulos de nodo adicionales no se pueden cargar directamente dentro de un nodo de función. Deben cargarse en el archivo settings.js y agregarse a la propiedad functionGlobalContext.
Por ejemplo, el módulo del sistema operativo integrado puede estar disponible para todas las funciones agregando lo siguiente al archivo settings.js.
functionGlobalContext: {
osModule:require('os')
} En ese momento, se puede hacer referencia al módulo dentro de una función como global.get (‘osModule’).
Los módulos cargados desde el archivo de configuración deben instalarse en el mismo directorio que el archivo de configuración. Para la mayoría de los usuarios, ese será el directorio de usuario predeterminado: ~/.node-red:
cd ~/.node-red
npm install name_of_3rd_party_module Reusar Nodos de Función
Se pueden guardar los nodos de función en la library y reutilizarlos en otros flujos importándolos. Para guardar una función en la library, haga doble clic en la función para editarla y haga clic en el icono de marcador junto al nombre de la función. Aparece un menú desplegable para importar o guardar la función.

También se puede utilizar un subflow para almacenar funciones. El uso de un subflujo los hace disponibles como nodos que puede seleccionar en la paleta de nodos de la izquierda.
Otros Objetos Disponibles
Objetos disponibles en el nodo función:
- node.id : the id of the Function node – added in 0.19
- node.name : the name of the Function node – added in 0.19
- node.log(..) : log a message
- node.warn(..) : log a warning message
- node.error(..) : log an error message
- node.debug(..) : log a debug message
- node.trace(..) : log a trace message
- node.on(..) : register an event handler
- node.status(..) : update the node status
- node.send(..) : send a message
- node.done(..) : finish with a message
context
- context.get(..): get a node-scoped context property
- context.set(..): set a node-scoped context property
- context.keys(..): return a list of all node-scoped context property keys
- context.flow : same as flow
- context.global : same as global
flow
- flow.get(..) : get a flow-scoped context property
- flow.set(..) : set a flow-scoped context property
- flow.keys(..) : return a list of all flow-scoped context property keys
global
- global.get(..) : get a global-scoped context property
- global.set(..) : set a global-scoped context property
- global.keys(..) : return a list of all global-scoped context property keys
RED
- RED.util.cloneMessage(..) : safely clones a message object so it can be reused
env
- env.get(..) : get an environment variable
El nodo Función también pone a disposición los siguientes módulos y funciones:
- Buffer – the Node.js Buffer module
- console – the Node.js console module (node.log is the preferred method of logging)
- util – the Node.js util module
- setTimeout/clearTimeout – the javascript timeout functions.
- setInterval/clearInterval – the javascript interval functions.