Una función es un bloque de código que tiene un nombre y un conjunto de instrucciones que son ejecutadas cuando se llama a la función. Son funciones setup() y loop() de las que ya se ha hablado.
Una función tiene un nombre y un conjunto de instrucciones que son ejecutadas cuando se llama a la función. Son funciones setup() y loop() de las que ya se ha hablado anteriormente.
Las funciones de usuario pueden ser escritas para realizar tareas repetitivas y para reducir el tamaño de un programa. Segmentar el código en funciones permite crear piezas de código que hacen una determinada tarea y volver al área del código desde la que han sido llamadas.
Una función puede llamarse múltiples veces e incluso llamarse a sí misma (función recurrente). Las funciones pueden recibir datos desde afuera al ser llamadas a través de los parámetros y puede entregar un resultado.
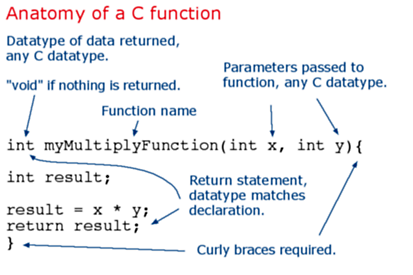
Las funciones se declaran asociadas a un tipo de valor. Este valor será el que devolverá la función, por ejemplo ‘int’ se utilizará cuando la función devuelva un dato numérico de tipo entero. Si la función no devuelve ningún valor entonces se colocará delante la palabra “void”, que significa “función vacía”
Sintaxis:
tipo nombreFunción (parámetros) {
instrucciones;
}
Para llamar a una función, simplemente:
nombreFunción(parámetros);
En una función que devuelve un valor siempre debe tener la instrucción Return, este termina una función y devuelve un valor a quien ha llamado a la función: http://arduino.cc/en/Reference/Return
Si se define una función y no ponemos return el valor devuelto es cero. No da error de compilación.
Ventajas del uso de funciones:
Ayuda a tener organizado el código.
Una función codifica una tarea en un lugar de nuestro sketch, así que la función solo debe ser pensada una sola vez.
Reduce la probabilidad de errores al modificar el código.
Hacen que el tamaño del sketch sea menor porque el código de la función es reutilizado.
Facilita la lectura del código.
Hace más sencillo reutilizar código en otros sketches.
Generalmente los nombres de las funciones deben ser en minúscula, con las palabras separadas por un guión bajo, aplicándose éstos tanto como sea necesario para mejorar la legibilidad.
“mixedCase” (primera palabra en minúscula) es aceptado únicamente en contextos en donde éste es el estilo predominante con el objetivo de mantener la compatibilidad con versiones anteriores.
En el caso de las clases, los nombres deben utilizar la convención “CapWords” (palabras que comienzan con mayúsculas).
Las funciones en Arduino pueden estar dentro del mismo fichero .ino o en otro fichero con extensión .ino dentro del directorio del sketch.
Paso por Valor y Paso por Referencia
Hasta ahora siempre hemos declarado los parámetros de nuestras funciones del mismo modo. Sin embargo, éste no es el único modo que existe para pasar parámetros.
La forma en que hemos declarado y pasado los parámetros de las funciones hasta ahora es la que normalmente se conoce como «por valor«. Esto quiere decir que cuando el control pasa a la función, los valores de los parámetros en la llamada se copian a «objetos» locales de la función, estos «objetos» son de hecho los propios parámetros.
int funcion(int n, int m) {
n = n + 2;
m = m - 5;
return n+m;
}
int a = 10;
int b = 20;
Serial.println(funcion(a,b));
Serial.println(funcion(10,20));
Empezamos haciendo a = 10 y b = 20, después llamamos a la función «funcion» con las objetos a y b como parámetros. Dentro de «funcion» esos parámetros se llaman n y m, y sus valores son modificados. Sin embargo al retornar al programa que lo llama, a y b conservan sus valores originales. Lo que pasamos no son los objetos a y b, sino que copiamos sus valores a los objetos n y m. Es lo mismo que hacer funcion(10,20), cuando llamamos a la función con parámetros constantes. Si los parámetros por valor no funcionasen así, no sería posible llamar a una función con valores constantes o literales.
Las referencias sirven para definir «alias» o nombres alternativos para un mismo objeto. Para ello se usa el operador de referencia (&).
Por ejemplo:
int a;
int& r = a; //Referencia a entero y debe siempre inicializarse
a = 10;
Serial.println(r);
En este ejemplo los identificadores a y r se refieren al mismo objeto, cualquier cambio en una de ellos se produce en el otro, ya que son, de hecho, el mismo objeto. El compilador mantiene una tabla en la que se hace corresponder una dirección de memoria para cada identificador de objeto. A cada nuevo objeto declarado se le reserva un espacio de memoria y se almacena su dirección. En el caso de las referencias, se omite ese paso, y se asigna la dirección de otro objeto que ya existía previamente. De ese modo, podemos tener varios identificadores que hacen referencia al mismo objeto, pero sin usar punteros.
El operador de dirección (&) devuelve la dirección de memoria de cualquier objeto
Los punteros se declaran igual que el resto de los objetos, pero precediendo el identificador con un asterisco (*)
int *pEntero;
int x = 10;
int y;
pEntero = &y; //pEntero apunta a la variable entera y
*pEntero = x; // y = 10
Si queremos que los cambios realizados en los parámetros dentro de la función se conserven al retornar de la llamada, deberemos pasarlos por referencia. Esto se hace declarando los parámetros de la función como referencias a objetos. Por ejemplo:
int funcion(int &n, int &m) {
n = n + 2;
m = m - 5;
return n+m;
}
int a = 10;
int b = 20;
Serial.println(funcion(a,b));
Serial.println("a = " + String(a) + " b = " + String(b));
Serial.println(funcion(10,20)); //es ilegal pasar constantes como parámetros cuando estos son referencias
En este caso, los objetos «a» y «b» tendrán valores distintos después de llamar a la función. Cualquier cambio de valor que realicemos en los parámetros dentro de la función, se hará también en los objetos referenciadas. Esto quiere decir que no podremos llamar a la función con parámetros constantes, ya que aunque es posible definir referencias a constantes, en este ejemplo, la función tiene como parámetros referencias a objetos variables. Y si bien es posible hacer un casting implícito de un objeto variable a uno constante, no es posible hacerlo en el sentido inverso. Un objeto constante no puede tratarse como objeto variable.
Una const reference es una referencia a que no permite cambiar la variable a través de esa referencia. Por ejemplo const int& r = a; en r tengo el valor de a pero no puedo cambiar el valor de a usando r.
No confundir este concepto con el modificador de variable static, que es utilizado para crear variables que solo son visibles dentro de una función, sin embargo, al contrario que las variables locales que se crean y destruyen cada vez que se llama a la función, las variables estáticas mantienen sus valores entre las llamadas a las funciones.
Hay operadores que tienen varios usos, como por ejemplo *, &, << o >>. Esto es lo que se conoce en C++ como sobrecarga de operadores. Con las funciones existe un mecanismo análogo, de hecho, en C++, los operadores no son sino un tipo especial de funciones, aunque eso sí, algo peculiares.
En C++ podemos definir varias funciones con el mismo nombre, con la única condición de que el número y/o el tipo de los argumentos sean distintos. El compilador decide cuál de las versiones de la función usará después de analizar el número y el tipo de los parámetros. Si ninguna de las funciones se adapta a los parámetros indicados, se aplicarán las reglas implícitas de conversión de tipos.
Las ventajas son más evidentes cuando debemos hacer las mismas operaciones con objetos de diferentes tipos o con distinto número de objetos. También pueden usarse macros para esto, pero no siempre es posible usarlas, y además las macros tienen la desventaja de que se expanden siempre, y son difíciles de diseñar para funciones complejas. Sin embargo las funciones serán ejecutadas mediante llamadas, y por lo tanto sólo habrá una copia de cada una.
Ejemplo:
int mayor(int a, int b);
char mayor(char a, char b);
float mayor(float a, float b);
int mayor(int a, int b, int c, int d);
int mayor(int a, int b) {
if(a > b) return a; else return b;
}
char mayor(char a, char b) {
if(a > b) return a; else return b;
}
float mayor(float a, float b) {
if(a > b) return a; else return b;
}
int mayor(int a, int b, int c, int d) {
return mayor(mayor(a, b), mayor(c, d));
}
Las llamadas a funciones sobrecargadas se resuelven en la fase de compilación. Es el compilador el que decide qué versión de la función debe ser invocada, después de analizar, y en ciertos casos, tratar los argumentos pasados en la llamadas. A este proceso se le llama resolución de sobrecarga.
Tener en cuenta que el tipo de retorno de la función no se considera en la sobrecarga de funciones. Consideremos el caso en el que desea escribir una función que devuelve un número aleatorio, pero se necesita una versión que devolverá un entero, y otra versión que devolverá un doble.
int getRandomValue();
double getRandomValue();
Pero el compilador toma esto como un error. Estas dos funciones tienen los mismos parámetros (ninguno) y en consecuencia, la segunda getRandomValue () serán tratada como una redeclaración errónea de la primera. En consecuencia, tendrán que ser dado diferentes nombres a estas funciones.
Una variable puede ser declarada al inicio del programa antes de la parte de configuración setup(), a nivel local dentro de las funciones, y, a veces, dentro de un bloque, como para los bucles del tipo if.. for.., etc. En función del lugar de declaración de la variable así se determinará el ámbito de aplicación, o la capacidad de ciertas partes de un programa para hacer uso de ella.
Una variable global es aquella que puede ser vista y utilizada por cualquier función y estamento de un programa. Esta variable se declara al comienzo del programa, antes de setup().
Recordad que al declarar una variable global, está un espacio en memoria permanente en la zona de static data y el abuso de variables globales supone un uso ineficiente de la memoria.
Una variable local es aquella que se define dentro de una función o como parte de un bucle. Sólo es visible y sólo puede utilizarse dentro de la función en la que se declaró. Por lo tanto, es posible tener dos o más variables del mismo nombre en diferentes partes del mismo programa que pueden contener valores diferentes, pero no es una práctica aconsejable porque complica la lectura de código.
NOTA: Hay una práctica del ámbito de las variables en el capítulo del curso de programación: “Prácticas: Variables y Tipos de Datos en Arduino”, Ejercicio07-Ambito_Variables
Inline
Cuando usamos el nombre de una función, indicando valores para sus argumentos, dentro de un programa, decimos que llamamos o invocamos a esa función. Esto quiere decir que el procesador guarda la dirección actual, «salta» a la dirección donde comienza el código de la función, la ejecuta, recupera la dirección guardada previamente, y retorna al punto desde el que fue llamada.
Esto es cierto para las funciones que hemos usado hasta ahora, pero hay un tipo especial de funciones que trabajan de otro modo. En lugar de existir una única copia de la función dentro del código, si se declara una función como inline, lo que se hace es insertar el código de la función, en el lugar (y cada vez) que sea llamada. Esta indica al compilador que cada llamada a la función inline deberá ser reemplazado por el cuerpo de esta función. En la práctica la función inline es utilizado sólo cuando las funciones son pequeñas para evitar generar un ejecutable de tamaño considerable.
La palabra reservada inline tiene la ventaja de acelerar un programa si éste invoca regularmente a la función inline. Permite reducir considerablemente el código, en particular para los accesadores de una clase. Un accesador de clase es típicamente una función de una línea.
Ejemplo:
inline int mayor(int a, int b) {
if(a > b) return a;
return b;
}
Primero recordar que en el lenguaje de Arduino al contrario que en estandar C, no es necesario declarar los prototipos de las funciones, puesto que de eso se encarga el de incluirlo el arduino builder, al igual que de añadir la función Main.
En C++ es obligatorio usar prototipos. Un prototipo es una declaración de una función. Consiste en una presentación de la función, exactamente con la misma estructura que la definición, pero sin cuerpo y terminada con un «;».
En general, el prototipo de una función se compone de las siguientes secciones:
Opcionalmente, una palabra que especifique el tipo de almacenamiento, puede ser extern o static. Si no se especifica ninguna, por defecto será extern.
El tipo del valor de retorno, que puede ser void, si no necesitamos valor de retorno.
Modificadores opcionales.
El identificador de la función. Es costumbre, muy útil y muy recomendable, poner nombres que indiquen, lo más claramente posible, qué es lo que hace la función, y que permitan interpretar qué hace el programa con sólo leerlos.
Una lista de declaraciones de parámetros entre paréntesis. Los parámetros de una función son los valores de entrada (y en ocasiones también de salida).
Un prototipo sirve para indicar al compilador los tipos de retorno y los de los parámetros de una función, de modo que compruebe si son del tipo correcto cada vez que se use esta función dentro del programa, o para hacer las conversiones de tipo cuando sea necesario.
Normalmente, los prototipos de las funciones se declaran dentro del fichero del programa, o bien se incluyen desde un fichero externo, llamado fichero de cabecera, (para esto se usa la directiva #include).
Ya lo hemos dicho más arriba, pero las funciones son extern por defecto. Esto quiere decir que son accesibles desde cualquier punto del programa, aunque se encuentren en otros ficheros fuente del mismo programa. En contraposición las funciones declaradas static sólo son accesibles dentro del fichero fuente donde se definen.
Si programamos en Arduino clases o librerías, es posible que debamos utilizar los prototipos de funciones.
Junto con los compiladores de C y C++, se incluyen ciertos archivos llamados bibliotecas más comúnmente librerías. Las bibliotecas contienen el código objeto de muchos programas que permiten hacer cosas comunes, como leer el teclado, escribir en la pantalla, manejar números, realizar funciones matemáticas, etc.
Las bibliotecas están clasificadas por el tipo de trabajos que hacen, hay bibliotecas de entrada y salida, matemáticas, de manejo de memoria, de manejo de textos y como imaginarás existen muchísimas librerías disponibles y todas con una función específica.
La declaración de librerías, tanto en C como en C++, se debe hacer al principio de todo nuestro código, antes de la declaración de cualquier función o línea de código, debemos indicarle al compilador que librerías usar, para el saber qué términos están correctos en la escritura de nuestro código y cuáles no. La sintaxis es la siguiente: #include <nombre de la librería> o alternativamente #include «nombre de la librería». En tu código puedes declarar todas las librerías que quieras aunque en realidad no tienen sentido declarar una librería que no vas a usar en tu programa, sin embargo no existe límite para esto.
La directiva de preprocesador #include se usa en los lenguajes C y C++ para “incluir” las declaraciones de otro fichero en la compilación. Esta directiva no tiene más misterio para proyectos pequeños. En cambio, puede ayudar aprovechar bien esta directiva en proyectos con un gran número de subdirectorios.
Ejemplo:
#include "iostream"
#include "string"
#include <math.h>
using namespace std;
Lo único adicional, es la línea que dice using namespace std; esta línea nos ayuda a declarar un espacio de nombre que evita tener que usarlo cada que accedemos a alguna función específica de una librería. Teniendo este namespace declarado podemos llamar por ejemplo el comando cout >>, que pertenece a la librería iostream, sin embargo sin este namespace sería std::cout >>, imagina tener que hacer esto cada vez que uses algún comando o función de las librerías, sería bastante tedioso.
Algunas de las librerías de uso más común de C++ y que forman parte de las librerías estándar de este lenguaje.
fstream: Flujos hacia/desde ficheros. Permite la manipulación de archivos desde el programar, tanto leer como escribir en ellos.
iosfwd: Contiene declaraciones adelantadas de todas las plantillas de flujos y sus typedefs estándar. Por ejemplo ostream.
iostream: Parte del a STL que contiene los algoritmos estándar, es quizá la más usada e importante (aunque no indispensable).
math: Contiene los prototipos de las funciones y otras definiciones para el uso y manipulación de funciones matemáticas.
memory: Utilidades relativas a la gestión de memoria, incluyendo asignadores y punteros inteligentes (auto_ptr). «auto_ptr» es una clase que conforma la librería memory y permite un fácil manejo de punteros y su destrucción automáticamente.
ostream: Algoritmos estándar para los flujos de salida.
Librería stdio: Contiene los prototipos de las funciones, macros, y tipos para manipular datos de entrada y salida.
Librería stdlib: Contiene los prototipos de las funciones, macros, y tipos para utilidades de uso general.
string: Parte de la STL relativa a contenedores tipo string; una generalización de las cadenas alfanuméricas para albergar cadenas de objetos.
vector: Parte de la STL relativa a los contenedores tipo vector; una generalización de las matrices unidimensionales C/C++
list: Permite implementar listas doblemente enlazadas (listas enlazadas dobles) fácilmente.
iterator: Proporciona un conjunto de clases para iterar elementos.
regex: Proporciona fácil acceso al uso de expresiones regulares para la comparación de patrones.
thread: Útil para trabajar programación multihilos y crear múltiples hilos en nuestra aplicación.
Arduino ya incluye diversas librerías por defecto sin llamarlas explícitamente, p.e. math.h
En la programación, una función anónima (función literal, abstracción lambda o expresión lambda) es una definición de función que no está vinculada a un identificador. Las funciones anónimas son a menudo argumentos que se pasan a funciones de orden superior, o que se utilizan para construir el resultado de una función de orden superior que necesita devolver una función. Si la función sólo se utiliza una vez, o un número limitado de veces, una función anónima puede ser sintácticamente más ligera que la que se utiliza con una función nombrada. Las funciones anónimas se utilizan en casi todos los lenguajes de programación.
En algunos lenguajes de programación, las funciones anónimas se implementan comúnmente para propósitos muy específicos, como la vinculación de eventos funciones de callback, o la instanciación de la función para valores particulares, que pueden ser más eficientes, más legibles y menos propensos a errores que la llamada a una función con nombre más genérico.
C++ soporta funciones anónimas, llamadas expresiones lambda, que tienen la forma::
Un ejemplo de función lambda se define de la siguiente manera:
[ ](int x, int y) -> int { return x + y; }
C++11 también soporta cierres. Los cierres (closures) se definen entre corchetes ([,]) en la declaración de expresión lambda. El mecanismo permite capturar estas variables por valor o por referencia. La siguiente tabla lo demuestra:
[ ] //no variables defined. Attempting to use any external variables in the lambda is an error.
[ x, &y ] //x is captured by value, y is captured by reference
[ & ] //any external variable is implicitly captured by reference if used
[ = ] //any external variable is implicitly captured by value if used
[ &, x ] //x is explicitly captured by value. Other variables will be captured by reference
[ =, &z ] //z is explicitly captured by reference. Other variables will be captured by value
Si en nuestro código tenemos múltiples funciones, podemos incluirlas en un fichero de C++ por ejemplo funciones.h, e incluyéndose en el principal con la instrucción #include “funciones.h”. En C++ el código se organiza en diferentes ficheros con extensiones .h y .cpp a los que se van llamando con #include para añadirlos al fichero que lo llama para poder usar su contenido.
Como se ha visto anteriormente, las librerías son trozos de código hechas por terceros que usamos en nuestro sketch. Esto nos facilita mucho la programación y hace que nuestro programa sea más sencillo de hacer y luego de entender. Más adelante veremos cómo hacer una librería.
Las librerías en Arduino incluyen los siguientes archivos comprimidos en un archivo ZIP o dentro de un directorio. Estas siempre contienen:
Un archivo .cpp (código de C++)
Un archivo .h o encabezado de C, que contiene las propiedades y métodos o funciones de la librería.
Un archivo Keywords.txt, que contiene las palabras clave que se resaltan en el IDE (opcional).
Muy posiblemente la librería incluye un archivo readme con información adicional de lo que hace y con instrucciones de como usarla.
Directorio denominado examples con varios sketchs de ejemplo que nos ayudará a entender cómo usar la librería (opcional).
Una librería a diferencia de las funciones debe estar al menos en un fichero diferente con extensión .h y opcionalmente en otro .cpp y además debe ser llamada con #include desde el sketch de arduino y estar en una ruta accesible desde el IDE de Arduino, ya sea el mismo directorio del sketch o en algunas de las rutas configuradas para librerías.
La ventaja de usar librerías frente a las funciones es que no es necesario incluir el código cada vez que se va a reutilizar sino que con tener la librería instalada en el IDE y llamarla mediante #include ya la puedo usar en mi código.
Al llamar a una librería desde un sketch, la librería completa es cargada a la placa de Arduino incrementando el tamaño del espacio usado en el microcontrolador, tanto en la memoria flash como en la RAM.
Las librerías que usamos para los sketches tienen una versión, que se suelen actualizar con frecuencia. También tenemos un control de versiones en el nuevo IDE a partir de 1.6.4 que nos facilita la gestión de la versión de las librerías usadas. Este aspecto es importante porque un sketch que funciona con una versión de una librería es posible que al compilarlo con otra versión en otro IDE no funcione. Por ello es importante documentar con que versión de librería está hecho o distribuir el sketch con la librería con la que se ha creado. Generalmente las librerías tienen compatibilidad hacia atrás, pero puede que no ocurra o que el comportamiento de la librería sea diferente.
Al cambiar el IDE también nos podemos encontrar que nuestro sketch no es compatible con la versión de la librería que estemos usando, que es diferente con la que se diseñó originalmente el sketch.
La instalación, actualización y manejo librerías en Arduino es un aspecto importante a la hora de usar Arduino, veamos unos ejemplos. Para aprender a instalar librerías lo mejor es practicar, veamos unos ejemplos de instalación de algunas librerías muy útiles.
Cuando se va a instalar una librería, la primera tarea es leer la documentación y aprender a usarla, ya sea leyendo el código, viendo los ejemplos o revisando la documentación si está disponible.
Pasos para realizar los ejemplos propuestos:
Leer la documentación y entender que hace la librería.
Buscar e instalar la librería desde el gestor de librerías, si está disponible.
Descargar el .zip del repositorio de github si no está en el gestor de librerías. Botón Download zip
Abrir alguno de los ejemplo suministrados por las librerías, leer el código, entender que hace y ejecutarlo en Arduino.
Desinstalar librerías: Para desinstalar una librería simplemente borrar el directorio de la librería situado en la ruta configurada en las preferencias de Arduino y reiniciar el IDE.
Librería MsTimer2
MsTimer2 nos ofrece muchas utilidades de temporización muy útiles en el trabajo diario con Arduino.
Instalar la librería MsTimer2 desde el gestor de librerías. Ejecutar el programa de ejemplo incluido en la librería para hacer blink (FlashLed) en el led integrado sin necesidad de usar la instrucción delay().
La librería Timer es otra de librería de muy interesante de temporización más flexible pero menos exacta de MsTimer2. Esta librería no está disponible en el gestor de librerías.
La librería Time que añade funcionalidades de mantenimiento de fecha y hora en Arduino sin necesidad de un hardware externo. También permite obtener fecha y hora como segundo, minuto, hora, día, mes y año.
Instalar la librería Time desde el gestor de librerías y ejecutar el ejemplo TimeSerial. Para ver la hora que debemos mandar a Arduino en el ejemplo ver https://www.epochconverter.com/
Librería para sonda temperatura/humedad DHT.
Librería para manejar un elemento HW como la sonda de temperatura y humedad DHT22.
Además de estas tres librerías, existen muchas más. Cualquiera de las librerías para la sonda DHT22 vale para usarla, pero cada una de ellas funciona diferente y cada una de ellas tiene sus ventajas e inconvenientes.
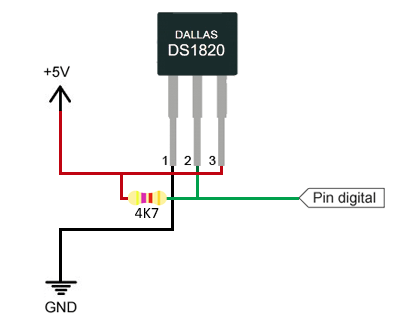
Un sonda de temperatura muy usada con Arduino es la DS18B20, esta usa un bus de comunicación multipunto llamado one wire, lo que nos permite leer muchas sondas con una sola i/o digital.
Esquema de montaje. El bus 1-Wire necesita una resistencia de pull-up de 4K7, y que podemos alimentar el sensor directamente a través del pin Vdd o usar el modo “parásito” y alimentarlo con la propia línea de datos.
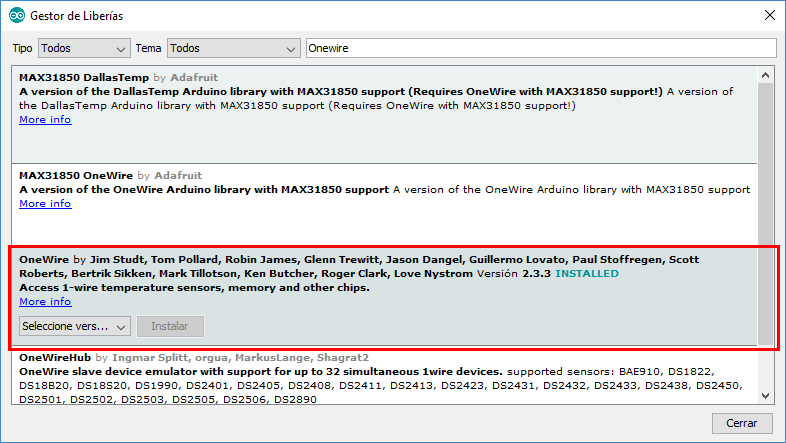
Para poder usar las sonda DS18B20 necesitaremos las librerías OneWire y DallasTemperature. Solo hay que buscar e instalar la librería a través del Gestor de Librerías.
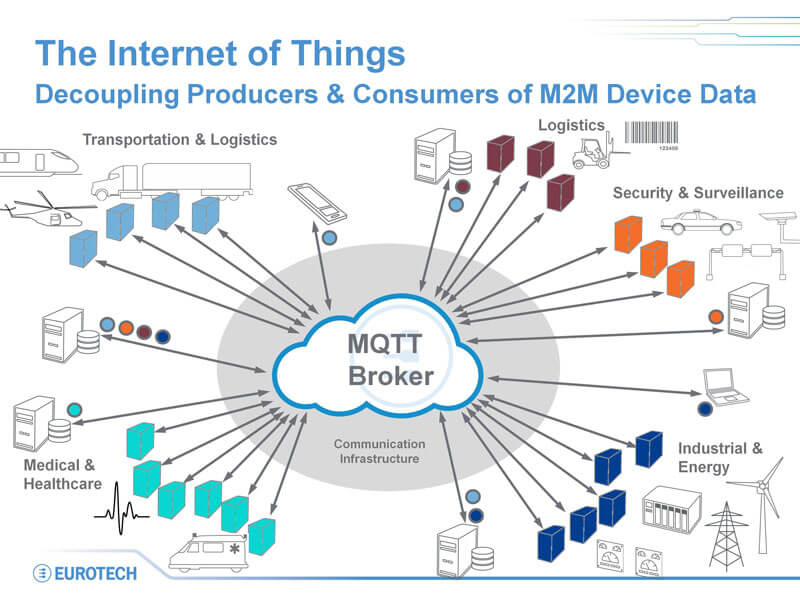
MQTT son las siglas de Message Queue Telemetry Transport y tras ellas se encuentra un protocolo ideado por IBM y liberado para que cualquiera podamos usarlo enfocado a la conectividad Machine-to-Machine (M2M).
MQTT fue creado por el Dr. Andy Stanford-Clark de IBM y Arlen Nipper de Arcom — ahora Eurotech — en 1999 como una forma rentable y confiable de conectar los dispositivos de monitoreo utilizados en las industrias del petróleo y el gas a servidores empresariales remotos. Cuando se les planteó el reto de encontrar la manera de enviar los datos de los sensores de los oleoductos en el desierto a sistemas SCADA externos (control de supervisión y adquisición de datos), decidieron utilizar una topología de publicación/suscripción basada en TCP/IP que se basaría en los eventos para mantener bajos los costos de transmisión de los enlaces satelitales.
Aunque MQTTT todavía está estrechamente asociado con IBM, ahora es un protocolo abierto que es supervisado por la Organización para el Avance de los Estándares de Información Estructurada (OASIS).
Está enfocado al envío de datos en aplicaciones donde se requiere muy poco ancho de banda. Además, sus características le permiten presumir de tener un consumo realmente bajo así como precisar de muy pocos recursos para su funcionamiento.
Estas características han hecho que rápidamente se convierta en un protocolo muy empleado en la comunicación de sensores y, consecuentemente, dentro del Internet de las Cosas.
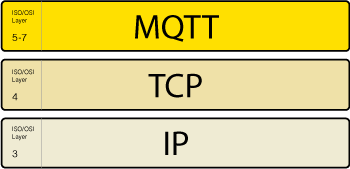
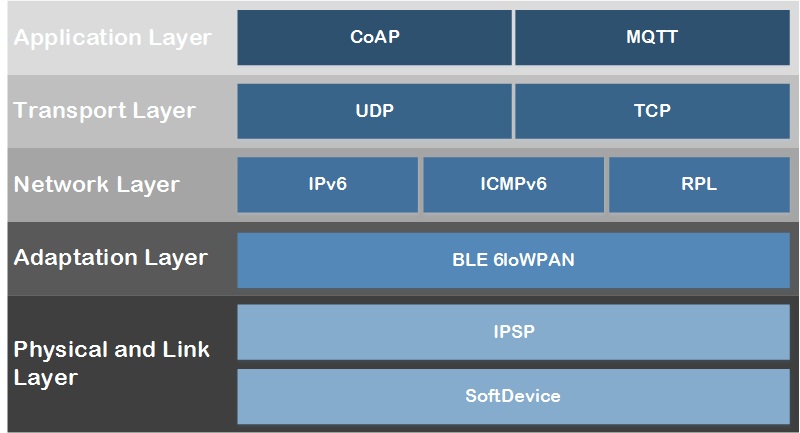
MQTT es un protocolo pensado para IoT que está al mismo nivel que HTTP o CoAP:
Comparativa MQTT y CoAP:
Un aspecto importante a tener en cuenta de los dispositivos IoT no es solamente el poder enviar datos al Cloud/Servidor, sino también el poder comunicarse con el dispositivo, en definitiva la bidireccionalidad. Este es uno de los beneficios de MQTT: es un modelo brokered, el cliente abre una conexión de salida al bróker, aunque el dispositivo esté actuando como Publisher o subscriber. Esto normalmente evita los problemas con los firewalls porque funciona detrás de ellos o vía NAT.
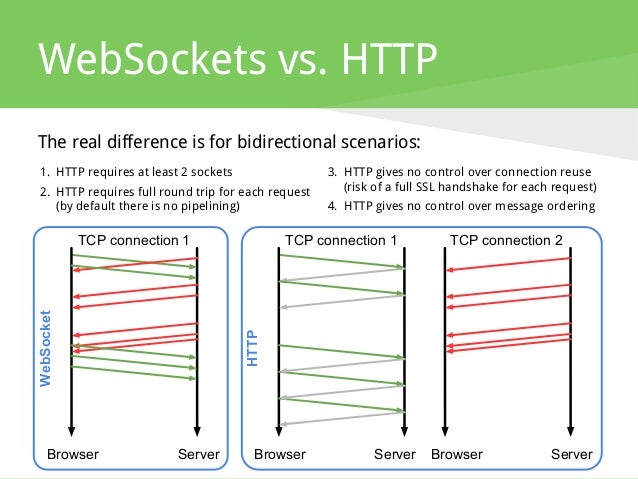
En el caso de que la comunicación principal se base en HTTP, la solución tradicional para enviar información al dispositivo sería HTTP Polling. Esto es ineficiente y tiene un coste elevado en aspectos de tráfico y/o energía. Una manera más novedosa de hacerlo sería con el protocolo WebSocket, que permite crear una conexión HTTP completa bidireccional. Esto actúa de canal socket (parecido al canal típico TCP) entre el servidor y el cliente. Una vez establecido, ya es trabajo del sistema escoger un protocolo para hacer un túnel sobre la conexión.
El Transporte de telemetría de cola de mensajes (MQTT) es un protocolo de código abierto que se desarrolló y optimizó para dispositivos restringidos y redes de bajo ancho de banda, alta latencia o poco confiables. Es un transporte de mensajería de publicación/suscripción que es extremadamente ligero e ideal para conectar dispositivos pequeños a redes con ancho de banda mínimo. El MQTT es eficiente en términos de ancho de banda, independiente de los datos y tiene reconocimiento de sesión continua, porque usa TCP. Tiene la finalidad de minimizar los requerimientos de recursos del dispositivo y, a la vez, tratar de asegurar la confiabilidad y cierto grado de seguridad de entrega con calidad del servicio.
El MQTT se orienta a grandes redes de dispositivos pequeños que necesitan la supervisión o el control de un servidor de back-end en Internet. No está diseñado para la transferencia de dispositivo a dispositivo. Tampoco está diseñado para realizar «multidifusión» de datos a muchos receptores. El MQTT es simple y ofrece pocas opciones de control. Las aplicaciones que usan MQTT, por lo general, son lentas en el sentido de que la definición de «tiempo real» en este caso se mide habitualmente en segundos.
MQTT también es un protocolo que está cobrando mucha importancia en la industria (IIoT). MQTT (Message Queuing Telemetry Transport, ‘Cola de mensajes telemetría y transporte’) es un protocolo publicar/suscribir diseñado para SCADA. Se centra en un mínimo encabezado (dos bytes) y comunicaciones confiables. También es muy simple. Tal como HTTP, la carga MQTT es específica para la aplicación, y la mayoría de las implementaciones usan un formato JSON personalizado o binario.
MQTT es interesante usarlo cuando el ancho de banda bajo y no conozca su infraestructura. Asegúrese de que su proveedor tenga un broker MQTT a quien le pueda publicar información, y siempre asegure la comunicación con TLS (Transport Layer Security, ‘seguridad en la capa de transporte’).
Por ejemplo, MQTT sería una buena opción para monitorizar y controlar los paneles solares. MQTT es un protocolo de publicación/suscripción con brokers de mensajes centrales. Cada panel solar puede contener un nodo IoT que publique mensajes de tensión, corriente y temperatura.
MQTT está diseñado para minimizar el ancho de banda, lo que lo convierte en una buena opción para el monitoreo satelital de la línea de transmisión, pero hay una trampa. La ausencia de metadatos en las cabeceras de los mensajes significa que la interpretación de los mensajes depende completamente del diseñador del sistema.
Para compensar las redes poco fiables, MQTT soporta tres niveles de Calidad de Servicio (QoS):
Disparar y olvidar (0) – Fire and Forget – At most once
Al menos una vez (1) – At least once
Exactamente una vez (2) – Exactly once
Si se solicita el nivel de calidad de servicio 1 ó 2, el protocolo gestiona la retransmisión de mensajes para garantizar la entrega. La calidad de servicio puede ser especificada por los clientes de publicación (cubre la transmisión del publicador al broker) y por los clientes suscriptores (cubre la transmisión de un broker a un suscriptor).
MQTT QoS 2 aumentará la latencia porque cada mensaje requiere dos handshake completos de ida y vuelta del remitente al receptor (cuatro en total del publicador al suscriptor).
En un patrón de publicación/suscripción es difícil saber la diferencia entre «Ha pasado mucho tiempo desde que supe de mi publicador» y «Mi publicador murió». Ahí es donde entra en juego la Última Voluntad y el Testamento (LWT) de MQTT. Los clientes pueden publicar mensajes sobre temas específicos (por ejemplo, aisle15/rack20/panel5/FalloSensor) para que se entreguen si se desconectan sin enviar un mensaje de «desconexión». Los mensajes se almacenan en el broker y se envían a cualquier persona que se haya suscrito al tema.
MQTT de un vistazo
Ancho de banda muy bajo
TCP/IP
Publicar/suscribir transferencia de mensajes
Topología de muchos a muchos a través de un broker central
Sin metadatos
Tres niveles de QoS
Última Voluntad y Testamento revela nodos desconectados
Las ventajas de usar el protocolo MQTT son:
Es asíncrono con diferentes niveles múltiples de calidad del servicio, lo que resulta ser importante en los casos donde las conexiones de Internet son poco confiables.
Envía mensajes cortos que se vuelven adecuados para las situaciones de un bajo ancho de banda.
No se requiere de mucho software para implementar a un cliente, lo cual lo vuelve fantástico para los dispositivos como Arduino con una memoria limitada.
Podemos cifrar los datos enviados y usar usuario y password para proteger nuestros envíos.
Si quisiera grabar en una BBDD con MQTT, un suscriptor a una serie de topics se encarga de grabar los datos cada vez que cambia un valor o cada cierto tiempo, por ejemplo con un script de python o ejecutando Node-RED en una máquina virtual o en el propio servidor (o Raspberry Pi) donde corre el broker (Mosquitto):
NodeRed no es más que un software que se instala en un nodo aunque se instale en el mismo servidor que el broker.
MQTT (Message Queue Telemetry Transport), un protocolo usado para la comunicación machine-to-machine (M2M) en el «Internet of Things». Este protocolo está orientado a la comunicación de sensores, debido a que consume muy poco ancho de banda y puede ser utilizado en la mayoría de los dispositivos empotrados con pocos recursos (CPU, RAM, …).
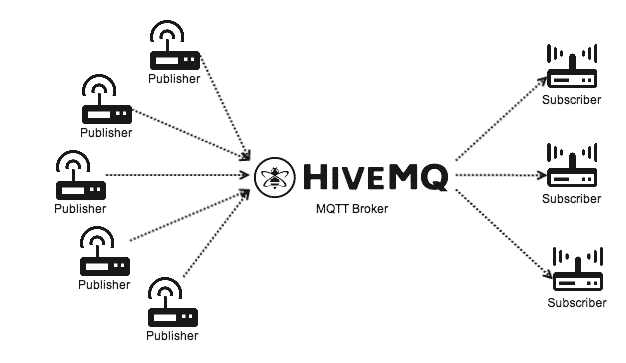
Un ejemplo de uso de este protocolo es la aplicación de Facebook Messenger tanto para android y iPhone. La arquitectura de MQTT sigue una topología de estrella, con un nodo central que hace de servidor o «broker». El broker es el encargado de gestionar la red y de transmitir los mensajes, para mantener activo el canal, los clientes mandan periódicamente un paquete (PINGREQ) y esperan la respuesta del broker (PINGRESP). La comunicación puede ser cifrada entre otras muchas opciones.
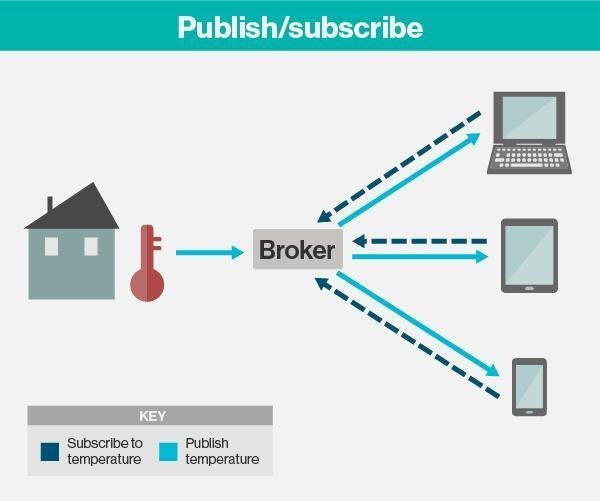
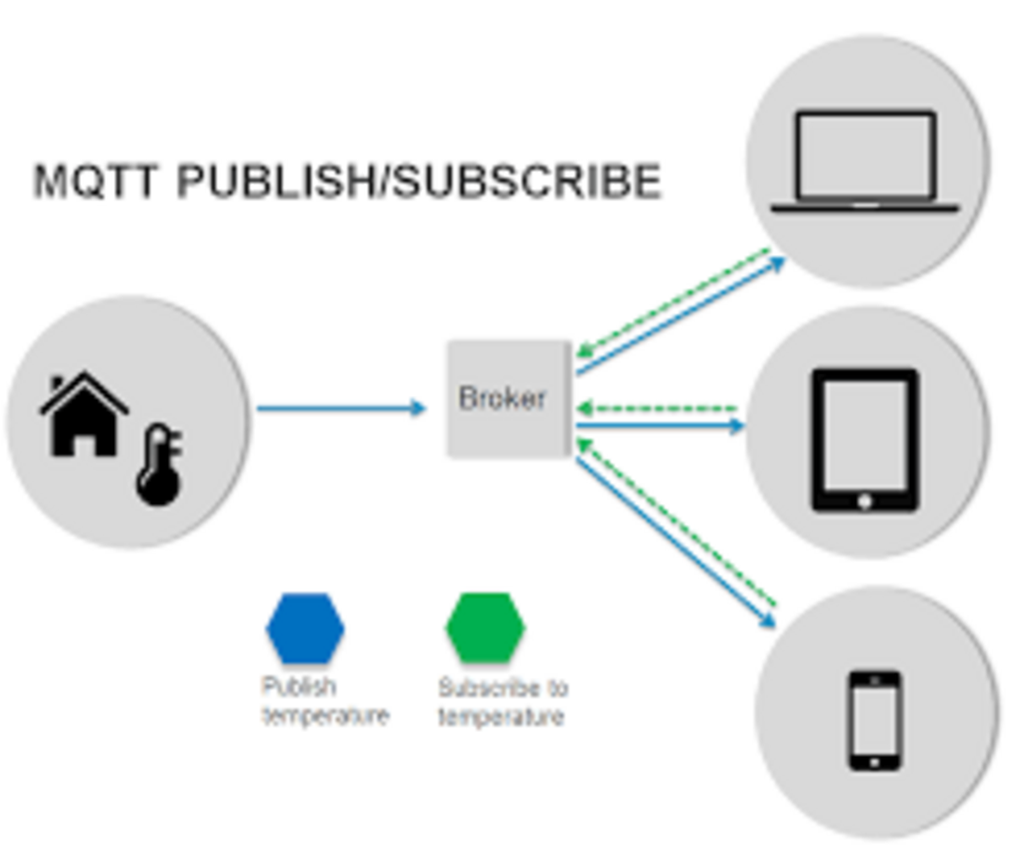
En esta forma de comunicación se desacoplan los clientes que publican (Publisher) de los que consumen los datos (Suscribers). Eso significa que los clientes no se conocen entre ellos unos publican la información y otros simplemente la consumen, simplemente todos tienen que conocer al message broker.
El desacoplamiento se produce en tres dimensiones:
En el espacio: El publicador y el suscriptor no tienen porqué conocerse.
En el tiempo: El publicador y el suscriptor no tienen porqué estar conectados en el mismo momento.
En la sincronización: las operaciones en cualquiera de los dos componentes no quedan interrumpidas mientras se publican o se reciben mensajes.
Es precisamente el broker el elemento encargado de gestionar la red y transmitir los mensajes.
Una característica interesante es la capacidad de MQTT para establecer comunicaciones cifradas lo que aporta a nuestra red una capa extra de seguridad.
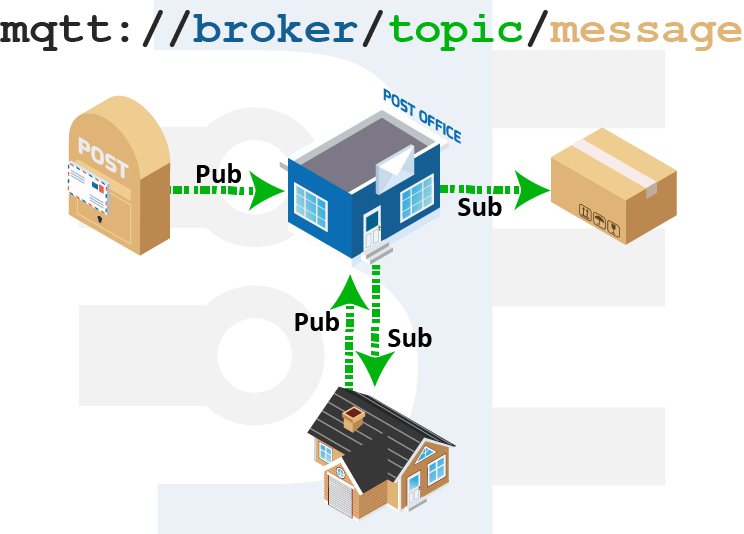
La comunicación se basa en unos «topics» (temas), que el cliente que publica el mensaje crea y los nodos que deseen recibirlo deben subscribirse a él. La comunicación puede ser de uno a uno, o de uno a muchos.
Dentro de la arquitectura de MQTT, es muy importante el concepto «topic» o «tema» en español ya que a través de estos «topics» se articula la comunicación puesto que emisores y receptores deben estar suscritos a un «topic» común para poder entablar la comunicación. Este concepto es prácticamente el mismo que se emplea en colas, donde existen un publicadores (que publican o emiten información) y unos suscriptores (que reciben dicha información) siempre que ambas partes estén suscritas a la misma cola.
Este tipo de arquitecturas, lleva asociada otra interesante característica: la comunicación puede ser de uno a uno o de uno a muchos.
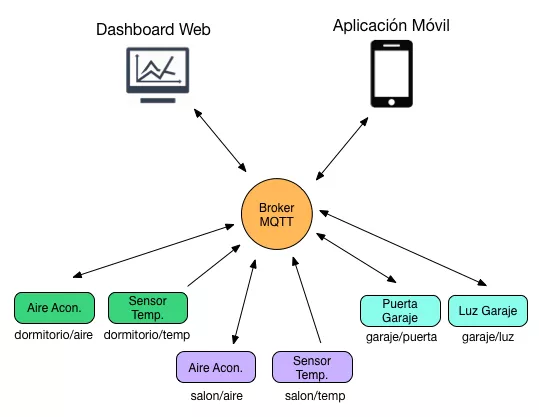
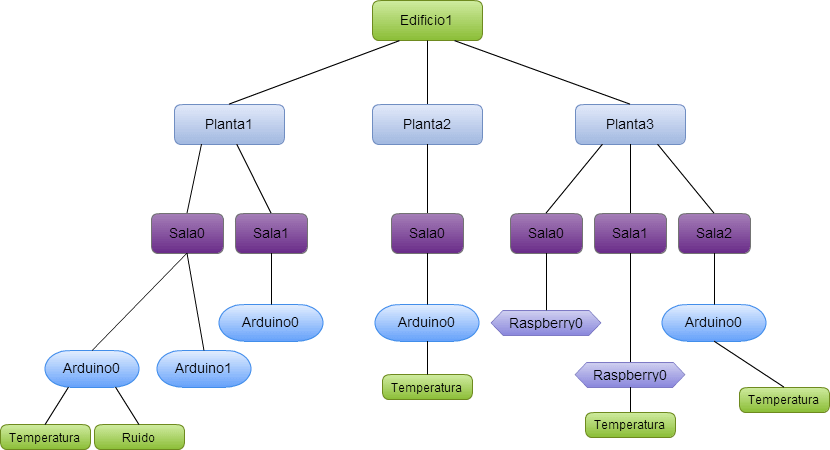
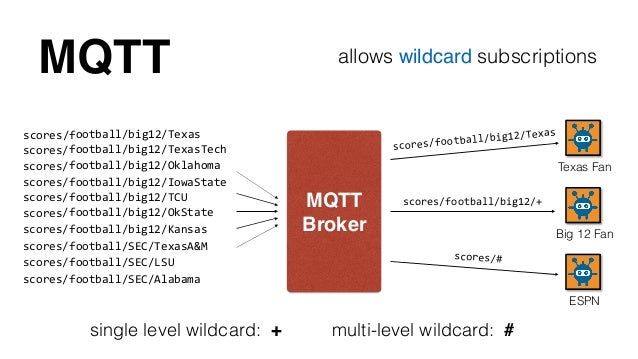
Un «topic» se representa mediante una cadena y tiene una estructura jerárquica. Cada jerarquía se separa con ‘/’.
Por ejemplo, «edificio1/planta5/sala1/raspberry2/temperatura» o «/edificio3/planta0/sala3/arduino4/ruido«. De esta forma se pueden crear jerarquías de clientes que publican y reciben datos, como podemos ver en la imagen:
De esta forma un nodo puede subscribirse a un «topic» concreto («edificio1/planta2/sala0/arduino0/temperatura») o a varios («edificio1/planta2/#»).
Existen dos comodines en MQTT para suscribirse a varios topics:
Multi-level Wildcard: # (se suscribe a todos los hijos bajo esa cola)
Single Level Wildcard: + (se suscribe solo a ese nivel)
Un carácter de tema especial, el carácter dólar ($), excluye un tema de cualquier suscripción de root wildcard. Normalmente, el $ se utiliza para transportar mensajes específicos del servidor o del sistema.
Ejemplos de Topics MQTT Válidos:
casa/prueba/topic
casa/+/topic
casa/#
casa/+/+
+/#
#
Explicación del comodín de single level:
Escalado MQTT
MQTT me permite gran escalabilidad. Añadir un nuevo Arduino o un suscriptor es muy sencillo dentro de la jerarquía vista
Con escalable me refiero a la capacidad que tiene un sistema para ser ampliado. Los sistemas de sensores en general, particularmente en nuestro caso hablamos del mundillo del Internet de las Cosas, se caracterizan por enviar muchos datos de pequeño tamaño en tiempo real ya que hay muchos sensores transmitiendo simultáneamente y cada breves periodos de tiempo, cuya información necesita ser consumida por otros elementos en tiempo real.
En una Arquitectura basada en Broker es fundamental evitar el SPOF (punto único de fallo).
En el contexto MQTT hay 2 estrategias principales:
Bridging: hace forward de mensajes a otro bróker MQTT. Es la solución de HiveMQ, Mosquitto, IBM MQ
Clustering: soportando añadido dinámico de nodos al cluster. Lo usa ActiveMQ, HiveMQ o RabbitMQ.
Cuando un sistema de estas características se empieza a saturar se bloquean las comunicaciones y se pierde la característica de «tiempo real».
Hasta ahora, todos los sistemas que habíamos visto se basaban en un cliente que se comunicaba con un servidor. Si cualquier cliente se intenta comunicar con un servidor que está procesando tanta información que, en ese momento, no es capaz de trabajar con más contenido, el sistema entero fallará, o bien porque se satura y bloquea a nivel global o porque empieza a descartar aquella información que no puede procesar (lo que es inadmisible en muchos caso, imagina una alarma de Riesgo de Explosión en tu cocina porque se ha detectado una fuga de gas…).
Existen varias formas de abordar esta problemática pero, a día de hoy, una de las más empleadas es usar sistemas de colas donde se deja toda la información y el encargado de procesarla va «sacando» de esta cola la información. De esta manera, si ponemos más «encargados de procesamiento» son capaces de vaciar más rápido la cola si viésemos que está se está empezando a llenar y, de cara a los sensores, no sería necesario hacer ningún cambio, ya que ellos siempre envían al mismo sitio.
MQTT no hace exactamente lo mismo ya que, para empezar, no hay colas sino «topics» pero la filosofía es muy parecida, permitiendo a grandes sistemas operar con total fluidez y, junto con sus optimizaciones que buscan entre otras cosas reducir consumos y tamaños de trama para poder operar en elementos embebidos, es el motivo por el que es un protocolo tan empleado en comunicaciones M2M.
Además, nos permite una gestión de la seguridad razonablemente sencilla que facilita que nuestros sistemas se comporten de una forma más robusta.
MQTT será el nexo entre hardware (sensor) y todos los elementos típicos del mundo software (servidores, bases de datos, Big Data). En esta capa nos preocupamos de que la información llegue a un sistema que posteriormente se ocupa de distribuirlo entre las demás partes y nos da igual lo que haya a partir de ese momento y su tamaño. Puede que no tengamos nada más que una web de visualización o puede que tengamos un complejo sistema de Machine Learning y Big Data. Puede que seamos un particular enviando un dato de temperatura a un panel de visualización en su Raspberry o puede que seamos una multinacional que controla en tiempo real su producción de amoniaco a nivel global bajando y subiendo la carga de producción en sus diferentes fábricas según los costes de transporte y el consumo de sus diferentes centros de distribución. Nos es lo mismo a este nivel porque nosotros hacemos sólo una cosa y la hacemos bien: enviar datos de un dispositivo hardware a un sistema mucho mayor. Es lo que se llama microservicios que ha popularizado netflix (http://enmilocalfunciona.io/arquitectura-microservicios-1/)
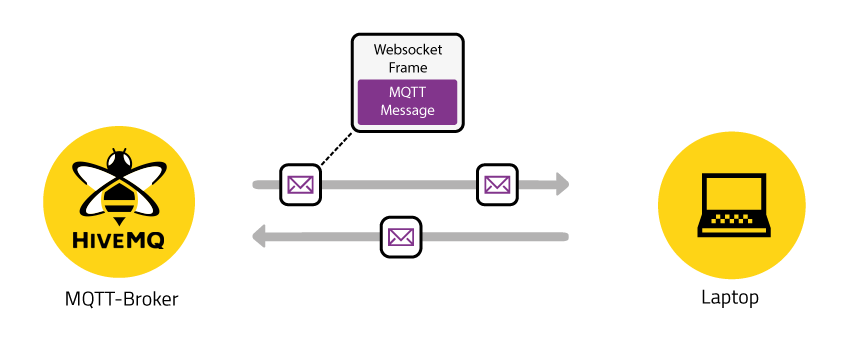
MQTT Sobre Websockets
MQTTT es una arquitectura de publicación/suscripción que se desarrolla principalmente para conectar dispositivos con ancho de banda y potencia limitada a través de redes inalámbricas. Es un protocolo simple y ligero que corre sobre sockets TCP/IP o WebSockets.
MQTT sobre WebSockets puede ser asegurado con SSL. La arquitectura de publicación/suscripción se basa en eventos que permiten enviar mensajes a los dispositivos cliente. El broker MQTT es el punto central de comunicación, y se encarga de despachar todos los mensajes entre los remitentes y los destinatarios legítimos. Un cliente es cualquier dispositivo que se conecta al corredor y puede publicar o suscribirse a temas para acceder a la información.
Un tema contiene la información de enrutamiento para el broker. Cada cliente que quiere enviar mensajes publica sobre un tema determinado, y cada cliente que quiere recibir mensajes se suscribe a un tema determinado. El corredor entrega todos los mensajes con el tema correspondiente a los clientes apropiados.
Sólo necesitará ejecutar MQTTT en sockets web si desea publicar/suscribirse a mensajes directamente desde webapps.
MQTT está diseñado para requerir una sobrecarga mínima del protocolo para cada paquete con el fin de preservar el ancho de banda para los dispositivos embebidos con recursos limitados. Es un marco de trabajo realmente sencillo para la gestión de redes mesh de dispositivos habilitados para TCP.
Los mensajes MQTT se entregan asincrónicamente («push») a través de la arquitectura publish subscribe. El protocolo MQTTT funciona intercambiando una serie de paquetes de control MQTT de una manera definida. Cada paquete de control tiene un propósito específico y cada bit del paquete se crea cuidadosamente para reducir los datos transmitidos a través de la red.
Una sesión MQTT se divide en cuatro etapas: conexión, autenticación, comunicación y terminación. Un cliente comienza creando una conexión TCP/IP con el broker utilizando un puerto estándar o un puerto personalizado definido por los operadores del broker. Al crear la conexión, es importante reconocer que el servidor puede continuar una sesión antigua si se le proporciona una identidad de cliente reutilizada.
Los puertos estándar son el 1883 para la comunicación no cifrada y el 8883 para la comunicación cifrada mediante SSL/TLS. Durante el handshake SSL/TLS, el cliente valida el certificado del servidor para autenticar el servidor.
MQTT es llamado un protocolo ligero porque todos sus mensajes tienen una pequeña huella de código. Cada mensaje consta de una cabecera fija, una cabecera variable opcional, una carga útil de mensaje limitada a 256 MB de información y un nivel de calidad de servicio (QoS).
MQTTT soporta BLOBS (Binary Large Object) de mensajes de hasta 256 MB de tamaño. El formato del contenido es específico de la aplicación. Las suscripciones de temas se realizan utilizando un par de paquetes SUBSCRIBE/SUBACK. La anulación de la suscripción se realiza de forma similar utilizando un par de paquetes UNSUBSCRIBE/UNSUBACK.
Durante la fase de comunicación, el cliente puede realizar operaciones de publicación, suscripción, cancelación (unsuscribe) y ping. La operación de publicación envía un bloque binario de datos, el contenido, a un topic definido por el publisher.
La operación de ping al servidor del broker usando una secuencia de paquetes PINGREQ/PINGRESP, que se usa para saber si está viva la conexión. Esta operación no tiene otra función que la de mantener una conexión en vivo y asegurar que la conexión TCP no ha sido apagada por una pasarela o un router.
Cuando un publicador o suscriptor desea finalizar una sesión MQTT, envía un mensaje DISCONNECT al broker y, a continuación, cierra la conexión. Esto se denomina “graceful shutdown” porque le da al cliente la posibilidad de volver a conectarse fácilmente al proporcionarle su identidad de cliente y reanudar el proceso donde lo dejó.
Si la desconexión ocurre repentinamente sin tiempo para que un publisher envíe un mensaje DISCONNECT, el broker puede enviar a los suscriptores un mensaje del publisher que el broker ha almacenado previamente en caché. El mensaje, que se llama testamento, proporciona a los suscriptores instrucciones sobre qué hacer si el editor muere inesperadamente.
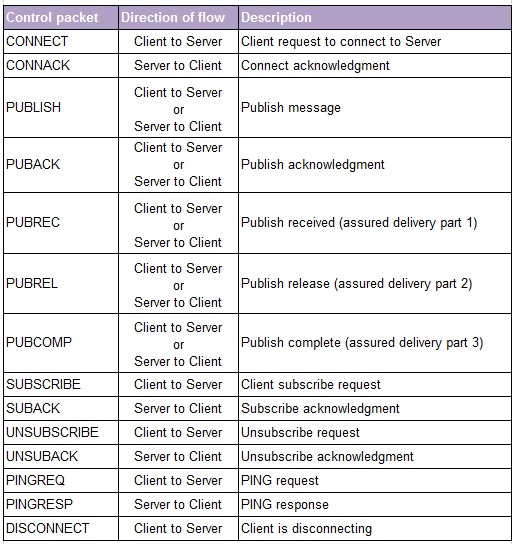
MQTT tiene 14 tipos de mensajes, normalmente un usuario sólo usa los mensajes de CONNECT, PUBLISH, SUBSCRIBE Y UNSUBSCRIBE. Si queréis conocer los tipos de mensajes podéis consultarlos en: https://dzone.com/refcardz/getting-started-with-mqtt
Al enviar mensajes MQTT existe la posibilidad que los mensajes no lleguen al destinatario.
El envío de mensajes sin saber con seguridad que fueron recibidos se llama «QoS 0» (cero).
Es posible que también desee QoS 1, que le permite saber que el mensaje fue recibido. Básicamente, después de cada publicación, el suscriptor dice «OK». En el lenguaje MQTT se llama «PUBACK» (Reconocimiento de publicación).
También está QoS 2, que no sólo garantiza que su mensaje fue recibido, sino que sólo fue recibido una vez. Esto es un poco más complejo porque necesitas empezar a rastrear los IDs de los paquetes, así que lo dejaremos para más adelante.
Los niveles de calidad de servicio (QoS) determinan cómo se entrega cada mensaje MQTT y deben especificarse para cada mensaje enviado a través de MQTT. Es importante elegir el valor de QoS adecuado para cada mensaje, ya que este valor determina la forma en que el cliente y el servidor se comunican para entregar el mensaje. Con el uso de MQTT se podrían lograr tres niveles de calidad de servicio para la entrega de mensajes:
QoS 0 (A lo sumo una vez – at most once) – donde los mensajes se entregan de acuerdo con los mejores esfuerzos del entorno operativo. Puede haber pérdida de mensajes. Confía en la fiabilidad del TCP. No se hacen retransmisiones.
QoS 1 (Al menos una vez – at least once) – donde se asegura que los mensajes lleguen, pero se pueden producir duplicados. El Receiver recibe el mensaje por lo menos una vez. Si el receiver no confirma la recepción del mensaje o se pierde en el camino el Sender reenvía el mensaje hasta que recibe por lo menos una confirmación. Pueden duplicarse mensajes.
QoS 2 (Exactamente una vez – exactly once) – donde se asegura que el mensaje llegue exactamente una vez. Eso incrementa la sobrecarga en la comunicación pero es la mejor opción cuando la duplicación de un mensaje no es aceptable.
Existe una regla simple cuando se considera el impacto del rendimiento de la QoS. Es «Cuanto mayor sea la QoS, menor será el rendimiento«. MQTT proporciona flexibilidad a los dispositivos de IoT para elegir la calidad de servicio apropiada que necesitarían para sus requisitos funcionales y ambientales.
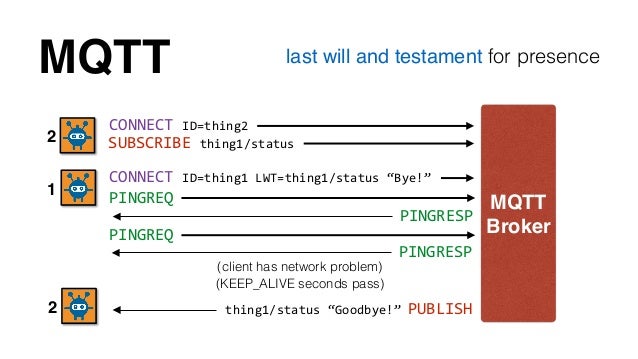
Último deseo y Testamento (MQTT LWT)
Un cliente puede establecer un mensaje Last Will and Testament (LWT) en el momento en el que conecta conecta con el Broker MQTT. Si el cliente no desconecta correctamente el Broker envía el mensaje LWT.
Cuando un cliente MQTT se conecta al servidor MQTT puede definir un tema y un mensaje que necesita ser publicado automáticamente sobre ese tema cuando se desconecta inesperadamente. Esto también se llama «Ultima voluntad y testamento» (LWT). Cuando el cliente se desconecta inesperadamente, el temporizador keep alive del lado del servidor detecta que el cliente no ha enviado ningún mensaje o el PINGREQ keep alive. Por lo tanto, el servidor publica inmediatamente el mensaje Will en el tema Will especificado por el cliente.
La función LWT puede ser útil en algunos escenarios. Por ejemplo, para un cliente MQTT remoto, esta función se puede utilizar para detectar cuando los dispositivos IoT salen de la red. La función LWT se puede utilizar para crear notificaciones para una aplicación que esté supervisando la actividad del cliente.
Cada mensaje MQTT puede ser enviado como un mensaje con retención (retained), en este caso cada nuevo cliente que conecta a un topic recibirá el último mensaje retenido de ese tópico.
Cuando un cliente conecta con el Broker puede solicitar que la sesión sea persistente (clean session = false), en ese caso el Broker almacena todas las suscripciones del cliente, todos los mensajes QoS 1 y 2 no procesados o perdidos por el cliente
Un mensaje MQTT CONNECT contiene un valor keepAlive en segundos donde el cliente establece el máximo tiempo de espera entre intercambio de mensajes
Seguridad MQTT
Ya sabemos lo importante que es la seguridad, y más en escenarios IoT en el que comunican objetos entre sí. MQTT confía en tecnologías estándares para esto:
Autenticación usuario/Password
Seguridad SSL/TLS
ACLs
Los puertos estándar son el 1883 para la comunicación no cifrada y el 8883 para la comunicación cifrada mediante SSL/TLS. Durante el handshake SSL/TLS, el cliente valida el certificado del servidor para autenticar el servidor. El cliente también puede proporcionar un certificado de cliente al broker durante el handshake, que el broker puede utilizar para autenticar al cliente. Aunque no forma parte específica de la especificación MQTT, se ha convertido en habitual que los broker admitan la autenticación de clientes con certificados SSL/TLS del lado del cliente.
Dado que el protocolo MQTTT pretende ser un protocolo para dispositivos con recursos limitados y de IoT, el SSL/TLS puede no ser siempre una opción y, en algunos casos, puede no ser deseable. En estos casos, la autenticación se presenta como un nombre de usuario y contraseña de texto claro que el cliente envía al servidor como parte de la secuencia de paquetes CONNECT/CONNNACK. Algunos brokers, especialmente los brokers abiertos publicados en Internet, aceptan clientes anónimos. En tales casos, el nombre de usuario y la contraseña simplemente se dejan en blanco.
Reto MQTT: Seguridad, Interoperabilidad y Autenticación
Debido a que el protocolo MQTT no fue diseñado con la seguridad en mente, el protocolo ha sido tradicionalmente utilizado en redes back-end seguras para propósitos específicos de la aplicación. La estructura temática de MQTT puede fácilmente formar un árbol enorme, y no hay una manera clara de dividir un árbol en dominios lógicos más pequeños que puedan ser federados. Esto dificulta la creación de una red MQTT globalmente escalable porque, a medida que crece el tamaño del árbol temático, aumenta la complejidad.
Otro aspecto negativo de MQTT es su falta de interoperabilidad. Debido a que las cargas útiles de mensajes son binarias, sin información sobre cómo están codificadas (sin metadatos), pueden surgir problemas, especialmente en arquitecturas abiertas en las que se supone que las diferentes aplicaciones de los diferentes fabricantes funcionan a la perfección entre sí.
MQTT tiene características de autenticación mínimas incorporadas en el protocolo. El nombre de usuario y las contraseñas se envían en texto claro y cualquier forma de uso seguro de MQTT debe emplear SSL/TLS, que, lamentablemente, no es un protocolo ligero.
Autenticar clientes con certificados del lado del cliente no es un proceso simple, y no hay manera en MQTT, excepto el uso de medios propietarios fuera de banda, para controlar quién posee un topic y quién puede publicar información sobre él. Esto hace que sea muy fácil inyectar mensajes dañinos, ya sea intencionadamente o por error, en la red.
Además, no hay forma de que el receptor del mensaje sepa quién envió el mensaje original a menos que esa información esté contenida en el mensaje real. Las características de seguridad que tienen que ser implementadas sobre MQTT de forma propietaria aumentan la huella de código (footprint) y hacen que las implementaciones sean más difíciles.
MQTT vs HTTP (REST API)
La diferencia entre una REST API y MQTT es que MQTT mantiene una conexión hacia el servicio abierta y puede responder mucho más rápido a los cambios en el feed. La REST API solo conecta al servicio cuando se hace una petición (request) y es más apropiada para proyecto donde el dispositivo permanece en modo sleep (para reducir el consumo) y despierta solo para mandar o recibir datos. (Push vs pull)
Push = websocket
Pull = REST API
HTTP no tiene estado (stateless), por lo que debe tener una conexión por cada transferencia de datos: una conexión cada vez que desee escribir datos, una conexión para la lectura. HTTP es ideal para grandes cantidades de datos, como los que se utilizan para sitios web, y se puede utilizar para conexiones IoT. Pero no es ligero y no es muy rápido. Otro problema con HTTP es que es sólo pull.
MQTTT es un gran protocolo. Es extremadamente sencillo y ligero. La conexión a un servidor sólo tarda unos 80 bytes. Usted permanece conectado todo el tiempo, cada dato ‘publicación’ (datos push de un dispositivo a otro) y cada dato ‘suscripción’ (datos push de un servidor a otro) es de unos 20 bytes. Ambos ocurren casi instantáneamente.
MQTT puede funcionar sobre cualquier tipo de red, ya sea una red mesh, TCP/IP, Bluetooth, etc.
Si se usa MQTT usando Bluetooth, XBee, Bluetooth LE, LoRA u otro protocolo y dispositivo no conectado a Internet, ¡necesitarás una pasarela!
Existen muchos clientes y librerías para MQTT, puesto que se trata de un protocolo libre sencillo de implementar.
Una aplicación de cliente MQTT se encarga de recopilar información del dispositivo de telemetría, conectar con el servidor y publicar la información en el servidor. También puede suscribirse a temas, recibir publicaciones y controlar el dispositivo de telemetría.
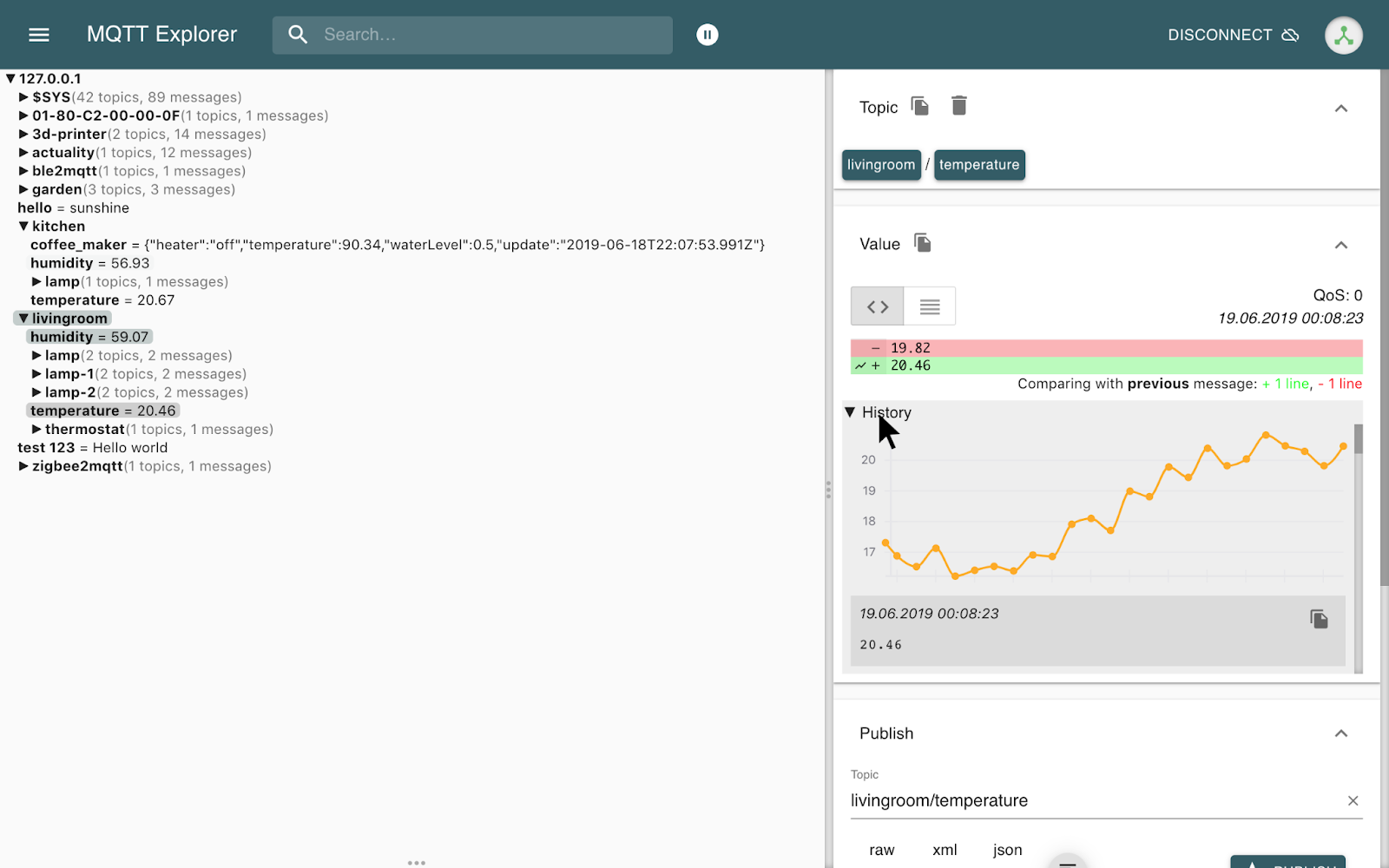
MQTT Explorer es un cliente MQTT integral que proporciona una descripción general estructurada de sus topics MQTT y hace que trabajar con dispositivos/servicios en su broker sea muy simple.
MQTT-spy es una utilidad de código abierto destinada a ayudarle a monitorear la actividad sobre temas de MQTTT. Ha sido diseñado para tratar con grandes volúmenes de mensajes, así como con publicaciones ocasionales.
mqtt-spy es probablemente una de las utilidades de código abierto más avanzadas para publicar y monitorear actividades sobre temas de MQTT. Está dirigido a dos grupos de usuarios:
Innovadores que necesitan una herramienta para crear prototipos de IO o proyectos de integración
Usuarios avanzados que necesitan una utilidad avanzada para sus entornos de trabajo
MQTT se puede instalar fácilmente a través de Google Chrome App Store. La herramienta tiene una interfaz bastante limpia y soporta todas las opciones de conexión disponibles desde la especificación MQTT, excepto las sesiones persistentes. Acepta conexiones a más de un broker al mismo tiempo y los colorea de manera diferente para facilitar su asociación.
La interfaz para suscribirse, publicar y ver todos los mensajes recibidos es simple y fácil de entender. Lamentablemente no hay posibilidad de publicar mensajes retenidos. Pero aunque esta aplicación se instala a través de Chrome, se ejecuta como una aplicación independiente.
MQTT ha surgido como un protocolo de mensajería estándar para la IoT. Se puede utilizar en redes TCP/IP y es muy ligero. La norma sigue un modelo de publicación-suscripción («pub/sub»).
Como habrás imaginado, para conseguir una comunicación MQTT, emplearemos una librería. Existen muchas disponibles gracias a la gran (tanto en tamaño como en calidad) comunidad que existe alrededor de Arduino.
Una de las librerías más conocidas y la más estable y flexible es Arduino Client for MQTT http://pubsubclient.knolleary.net/ que nos provee de un sencillo cliente que nos permite tanto subscribirnos como publicar contenido usando MQTT. Internamente, usa la API de Arduino Ethernet Client lo que lo hace compatible con un gran número de shields y placas.






























{kind=link}
{kind=link}