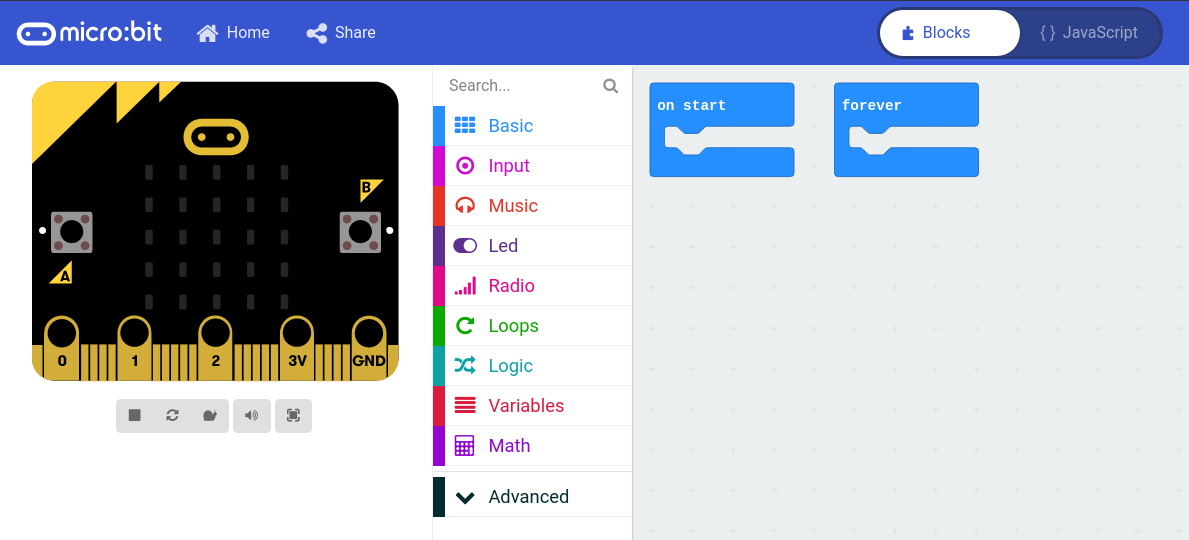
Micro:bit tiene un entorno de programación gráfico propio: MakeCode de Microsoft, un sencillo editor gráfico online muy potente y gratuito que posibilita introducirnos en el mundo de la programación de forma intuitiva a través del lenguaje de programación visual o de bloques. Con él aprendemos a pensar como un programador sin caer en los molestos errores de sintaxis. MakeCode es, sin duda, una herramienta a tener muy en cuenta por nuestros profesores.
BBC micro: bit también se puede programar con JavaScript, Pyton y Scratch (añadiendo una extensión).
MakeCode es una herramienta online de programación gráfica muy potente e intuitiva. También incluye un simulador para comprobar el funcionamiento antes de cargarlo en la placa.
Tras conectar la micro:BIT al ordenador, aparece esta como una nueva unidad. Terminado el programa y comprobado su correcto funcionamiento, se debe pulsar sobre el icono de descarga, lo que copia el código al ordenador con un nombre por defecto. Otra opción es introducir el nombre elegido en la caja situada al lado del icono del disco y pulsar sobre este para descargar. Ya solo queda copiar el fichero
Copiado el código, el programa comienza a ejecutarse de forma automática. Si se quiere usar la micro:BIT desconectada del ordenador, se debe conectar un pack de pilas o batería al conector situado junto al conector microUSB e inmediatamente se ejecutará el código descargado.
Una opción más recomendable es conectar el dispositivo:
Las extensiones son módulos de código funcional que se instalan desde fuera del editor MakeCode y conectan nuevos bloques a Toolbox. Estos bloques son creados por otros autores u organizaciones para hacer cosas que van desde simplificar tareas de codificación hasta trabajar con dispositivos de hardware.
Las extensiones también son conocidas como paquetes.
En caso que no nos reconozca el puerto serie M5Burner, habrá que instalar el driver como hemos hablado anteriormente desde: https://m5stack.com/pages/download
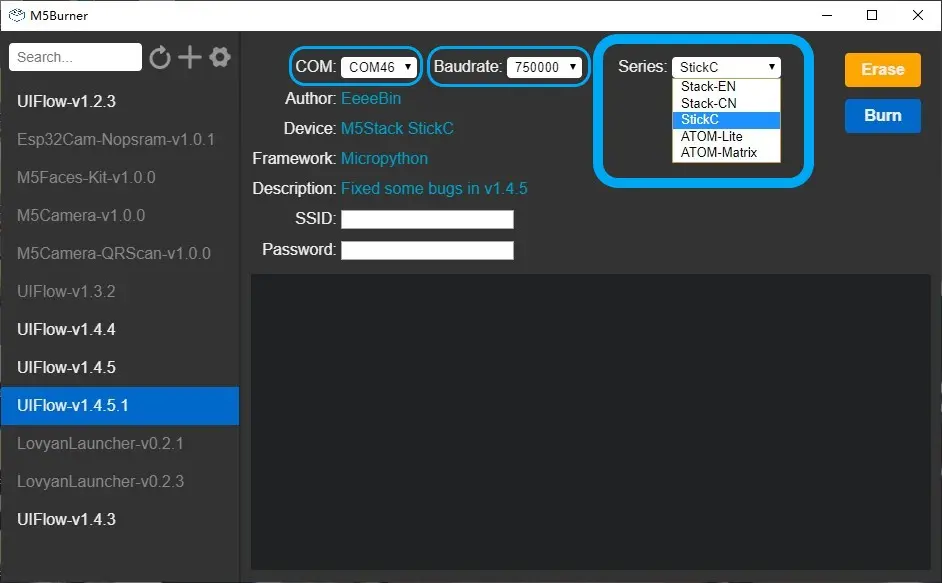
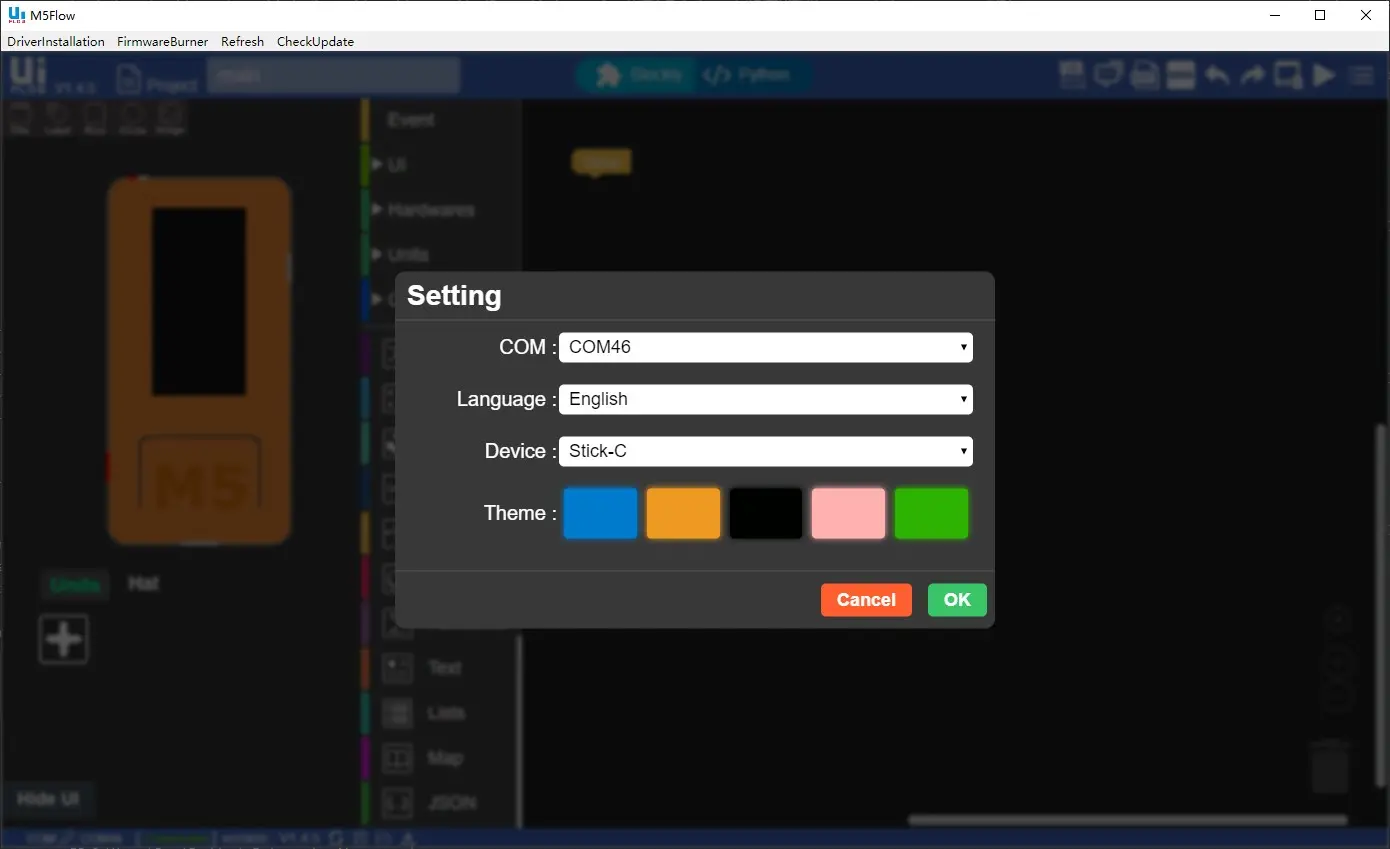
A la hora de cargar el firmware, seleccionar la versión de UIFlow que se va a usar en http://flow.m5stack.com/ y en caso que no aparezca resaltada, descargarla.
Luego seleccionar el puerto serie y el modelo de M5Stack que vamos a usar y por último configurar la wifi a la que se va a conectar para programar on-line.
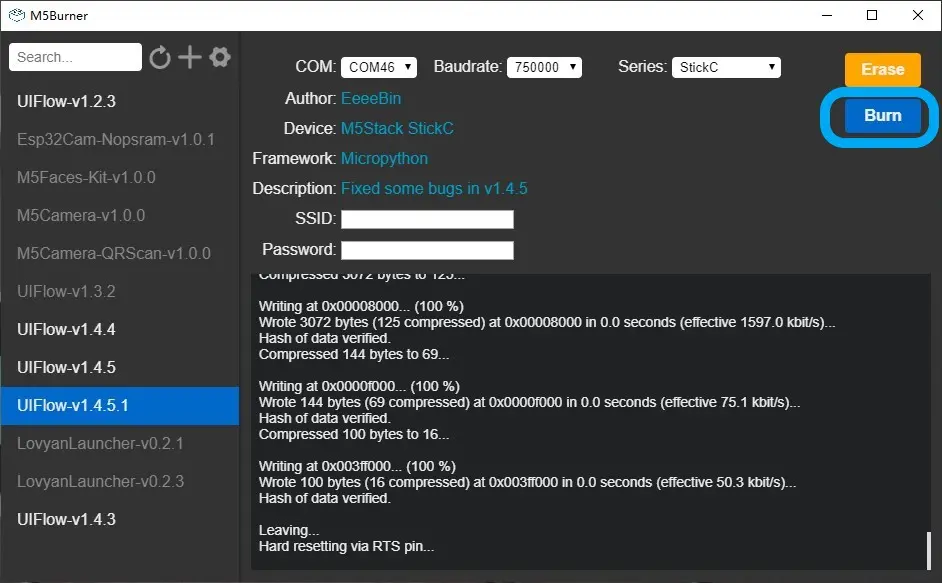
Y pulsar el botón burn, si da fallo probar a reducir el baudrate por defecto o borrar la flash con el botón erase.
En caso que no se haya configurado la wifi o no esté disponible la wifi, el M5Stack se configura como un AP Hotspot donde abre una red wifi a la que me puedo conectar y entrar a la web para configurar la wifi.
Modo Programación en Red
El modo de programación de red es un modo de acoplamiento entre el dispositivo M5Stack y la plataforma de programación web UIFlow. La pantalla mostrará el estado actual de la conexión de red del dispositivo. Cuando el indicador está en verde, significa que puede recibir un programa push en cualquier momento. Después de la primera configuración exitosa de la red WiFi, el dispositivo se reiniciará automáticamente e ingresará al modo de programación de red.
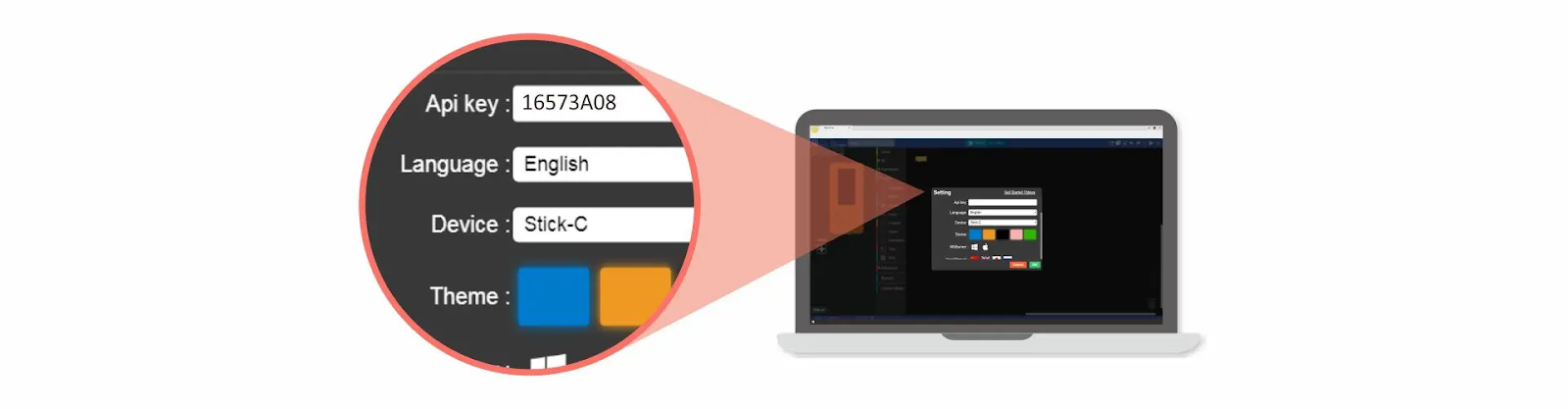
Una vez que el M5Stack tiene cargado el firmware y se inicia, se conectará a la wifi configurada y nos mostrará en pantalla el API KEY:
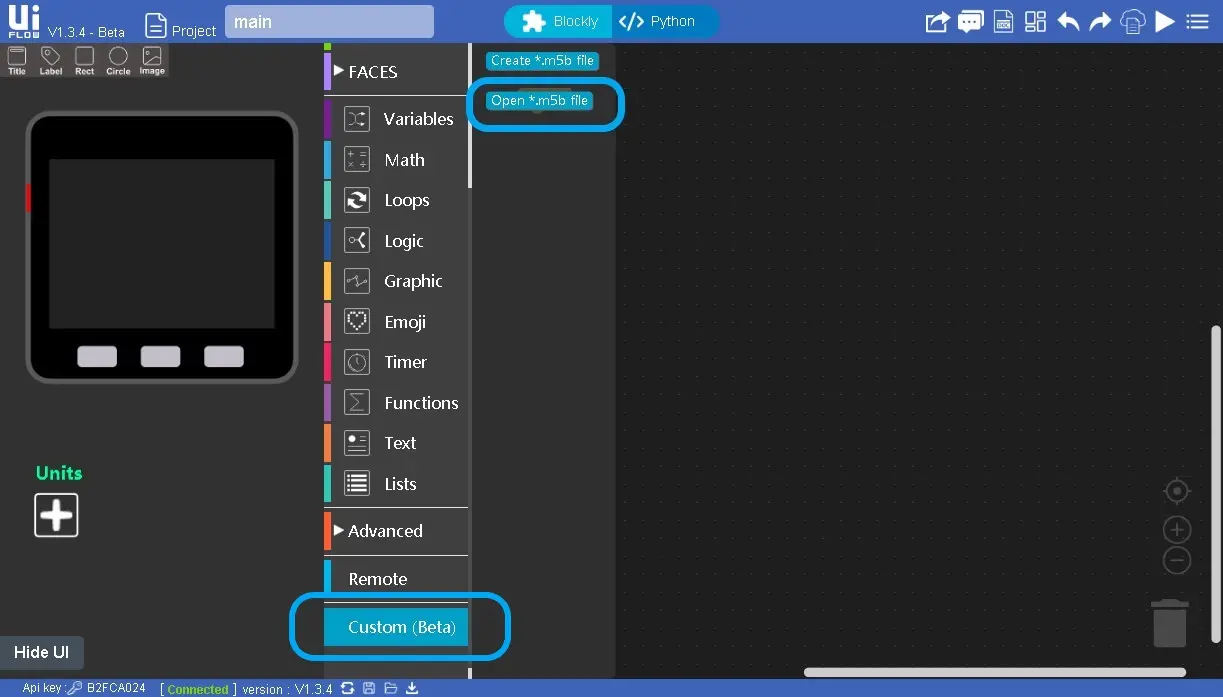
Una vez conectado y con el icono en verde, ya puedo entrar en http://flow.m5stack.com/ y emparejar el dispositivo M5 para programarlo. Para ello debo indicar el APIKEY y el dispositivo.
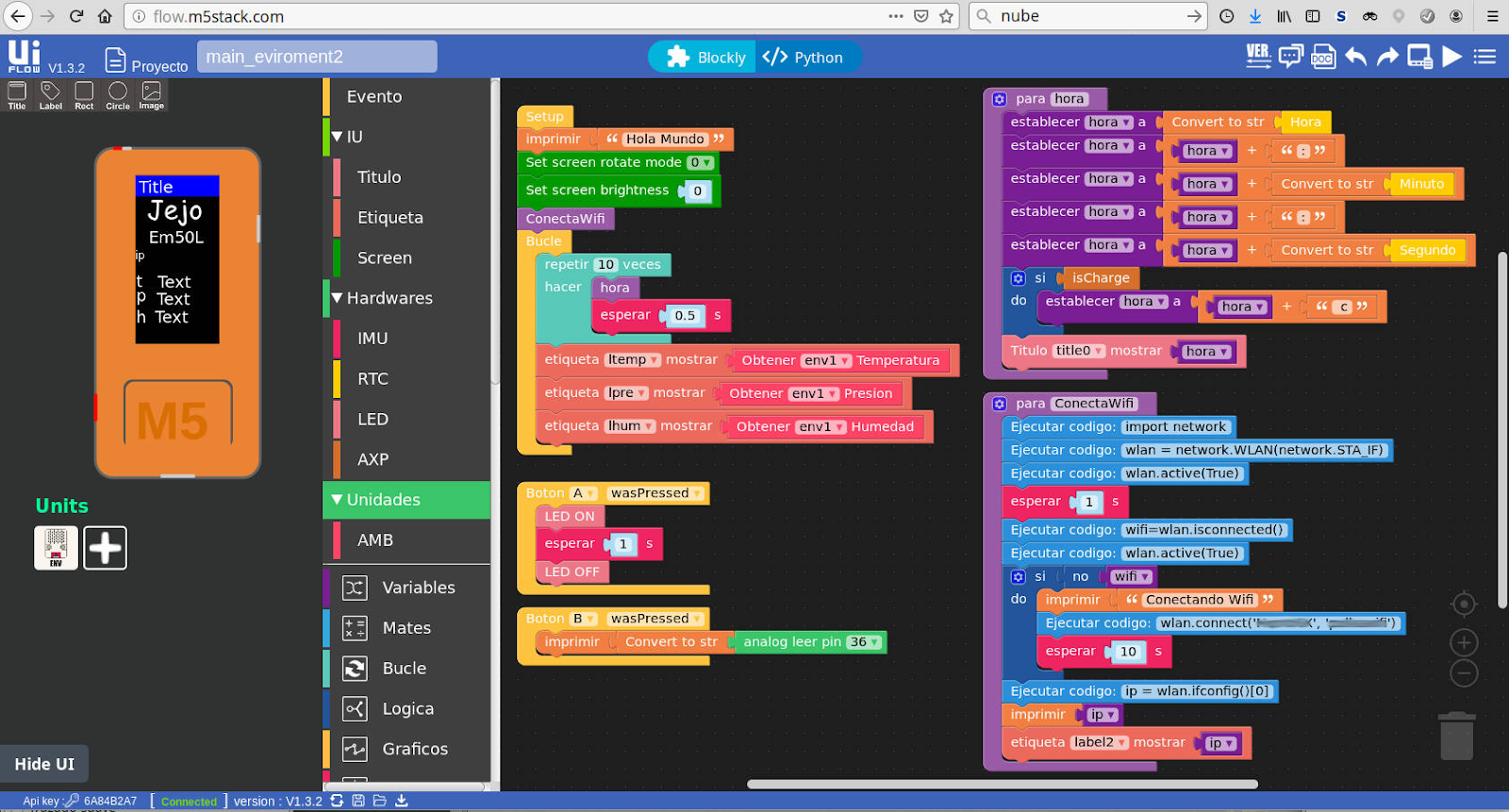
Una vez hecho esto ya se puede comenzar a programar con UIFlow. Lo siguiente le mostrará un programa simple para manejar M5StickC.
Para encender el indicador LED:
Arrastre el LED para iluminar el bloque de programa.
Empalme con el programa de inicialización de configuración.
Haga clic en el botón Ejecutar en la esquina superior derecha
Modo Programación USB
UIFlow Desktop IDE es una versión offline del programador UIFlow que no requiere conexión de red y puede ser una alternativa en caso de no tener acceso a Internet o una conexión lenta . Haga clic en la versión correspondiente de UIFlow-Desktop-IDE para descargar de acuerdo con su sistema operativo en https://m5stack.com/pages/download
Una vez instalado, detectará automáticamente si su ordenador tiene un controlador USB (CP210X), haga clic en Instalar y siga las instrucciones para finalizar la instalación. M5StickC no requiere un controlador CP210X, por lo que los usuarios pueden elegir instalar u omitir.
Cuando se inicie la aplicación, ya podemos conectar nuestro dispositivo M5
Para poder programar como USB, debemos entrar en modo USB, para ello: Haga clic en el botón de encendido en el lado izquierdo del dispositivo para reiniciar. Seleccione rápidamente Configuración después de ingresar al menú, ingrese a la página de configuración y seleccione el modo USB.
Y por último seleccionar el puerto serie y el dispositivo en el programa para empezar a usarlo.
Independientemente si usamos la versión online o la versión offline, la programación es igual.
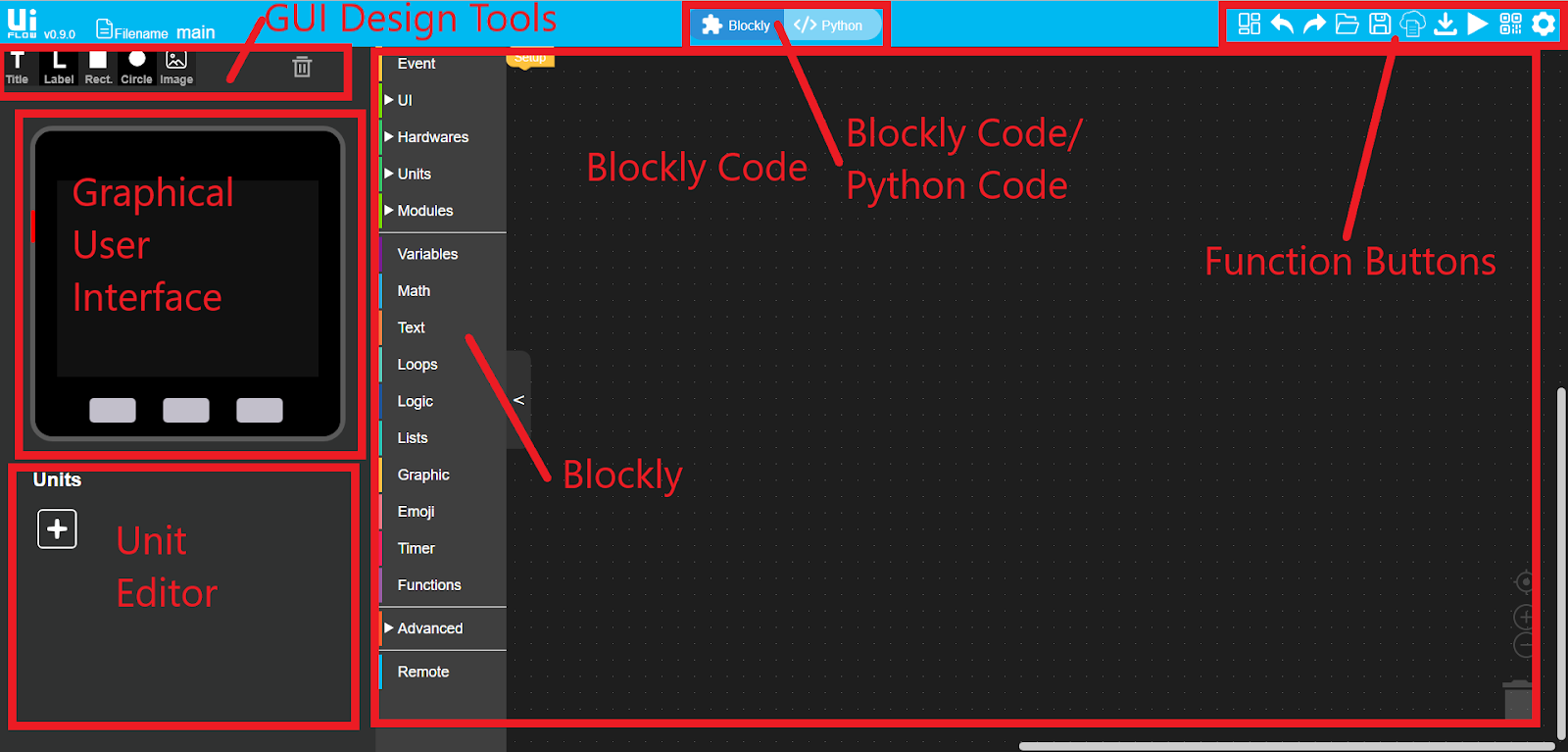
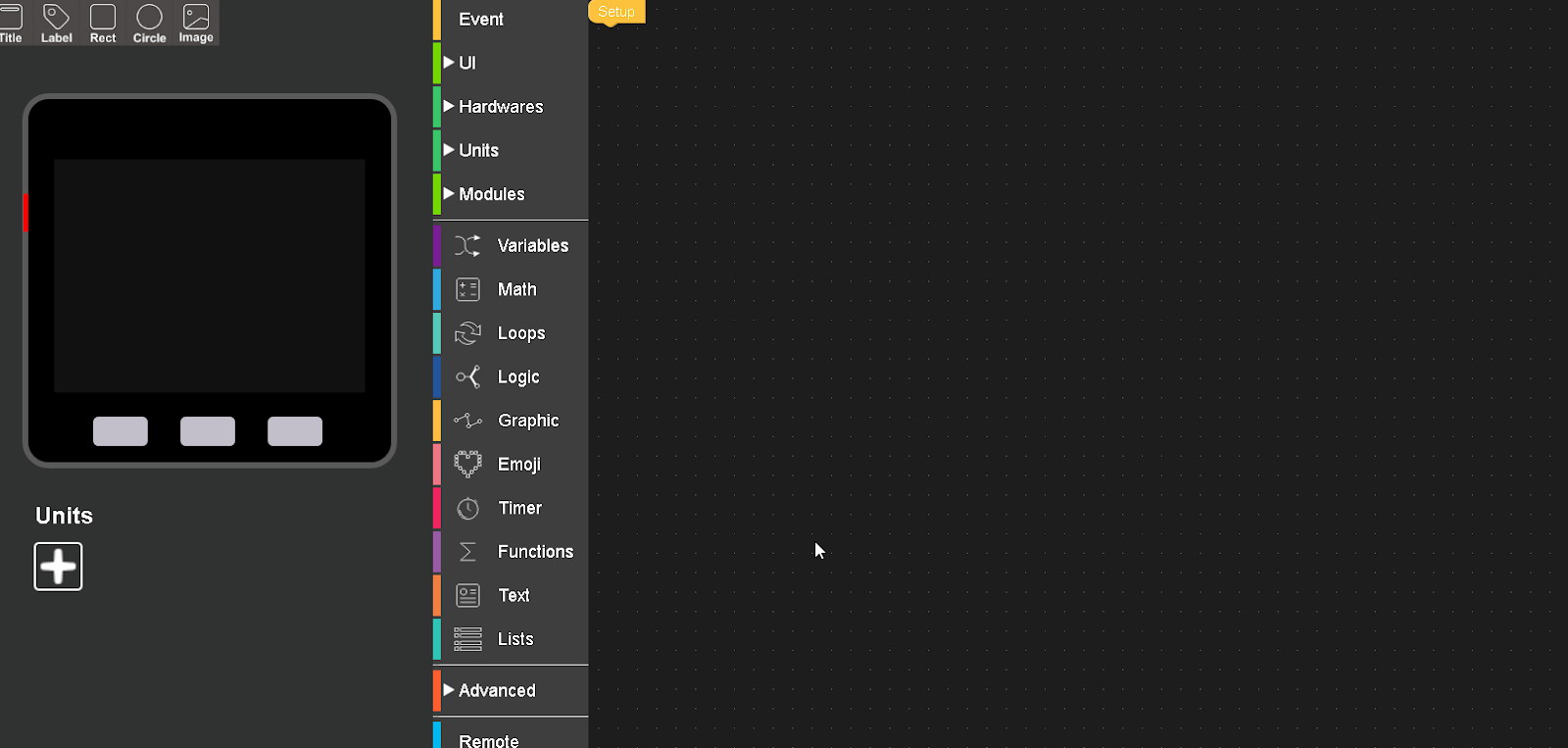
El entorno de programación se compone de 5 partes principales:
Coding Area: Arrastre los bloques de código de la lista de bloques al área de codificación y conéctelos para crear un programa
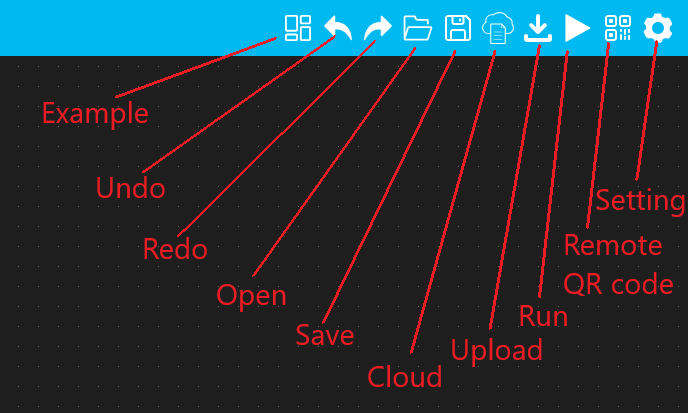
Barra de menús: La barra de menú contiene la mayoría de las funciones importantes de la interfaz, como (Ejemplo,Deshacer y rehacer, cargar, ejecutar código, descargar código, guardar código, etc.
Blockly/Python: Todo el código que creamos en bloques se puede convertir a Python presionando este interruptor
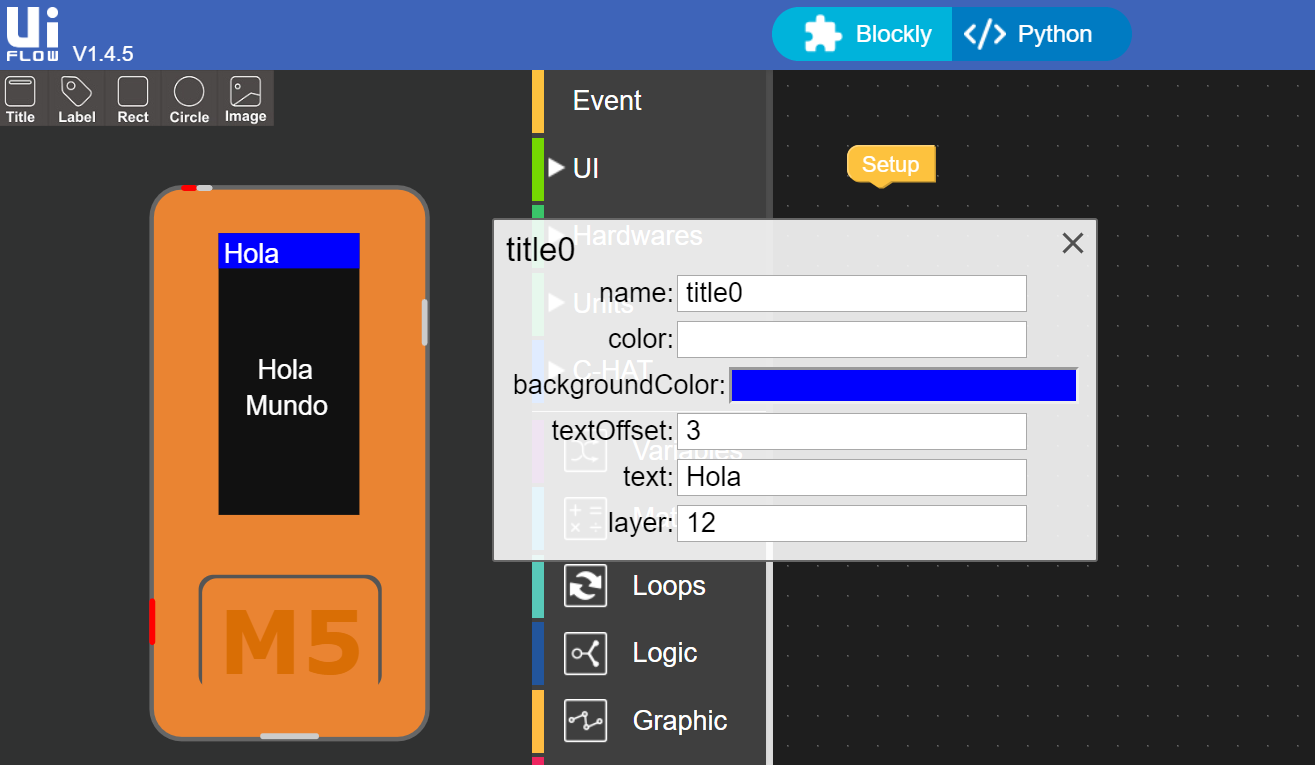
Diseñador de UI: Arrastre los elementos de la interfaz de usuario (título, etiqueta, etc.) hacia la pantalla de para diseñar un avatar o interfaz de interfaz de usuario.
Unidades: Las unidades son sensores y actuadores que se pueden conectar y aquí es donde los configuramos.
Funciones de los botones:
Programación con Blockly:
Programación Básica
Para la programación vamos a usar estas tres documentaciones oficiales:
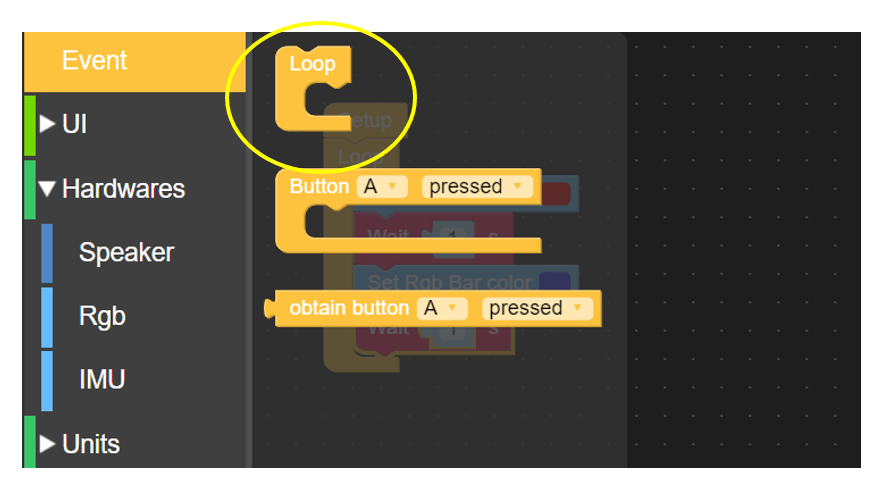
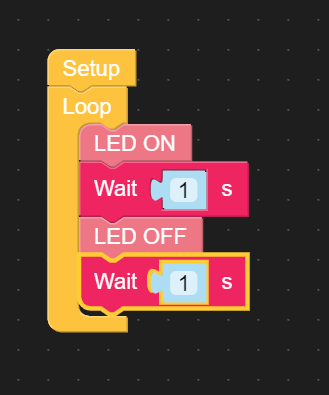
Setup: Cuando abra UIFlow, encontrará que ya hay un bloque de Configuración al principio. Cada programa debe tener un bloque de configuración. El programa se ejecuta desde el bloque de Configuración y solo se ejecutará una vez. Puedes considerarlo como un bloque de inicialización del programa
Loop: Loop es un bloque de bucle infinito. Cuando se ejecuta, ejecutará el programa contenido en el bloque indefinidamente hasta que ocurra algún evento que lo detenga, por ejemplo un reset o apagado. No tiene que existir en el programa, pero para que el programa ejecute funciones cíclicas debe usarse.
¿Cuál es la diferencia entre ejecutar y descargar un programa? El botón de reproducción coloca nuestro código en la memoria volátil de su M5stack. Lo que significa que se perderá una vez que apague el M5stack. Sin embargo, la función de descarga almacenará su programa en la memoria flash de su dispositivo que no se borrará al reiniciar. Cada vez que enciende el M5stack después de descargar un programa, ese programa se ejecutará automáticamente, y también puede seleccionarlo de la lista de aplicaciones a la que se accede presionando el botón central al iniciar.
Ejecutar un programa: Una vez que haya terminado de programar, presione el botón de reproducción en la esquina superior derecha para ejecutar su código.
Descargar un programa: almacenará su programa en la memoria flash de su dispositivo que no se borrará al reiniciar.
La aplicación grabada se podrá seleccionar desde el menú de aplicaciones del dispositivo M5 y se ejecutará en el inicio cada vez que se resetee. Para volver al entorno de programación y cambiar el programa, si tengo una aplicacion en modo permanente, reiniciar y pulsar el botón mientras arranca para entrar en modo programación cloud o USB.
Unidades y HATs
La unidad o HAT es un módulo hardware de expansión de funciones proporcionado por el sistema M5. Estas deben conectarse al módulo M5 antes de programarlas.
Los módulos y faces de M5Stack ya aparecen automáticamente al seleccionar el HW Core.
Las unidades deben se añadidas en UIFlow para que aparezcan sus bloques de programación. Haga clic en la opción Units debajo del Simulador de UI, marque el módulo de Unidad que desea agregar y haga clic en Aceptar. Algunas unidades tienen configuraciones iniciales de parámetros.
Las funciones son una herramienta que nos ayuda a envolver nuestro código en un paquete ordenado al que podemos asignarle un nombre, y luego llamarlo en cualquier parte de nuestro programa y ejecutará el código que contiene. Las funciones pueden ayudar a mantener nuestro código ordenado y conciso y evitar repetir las mismas cosas una y otra vez.
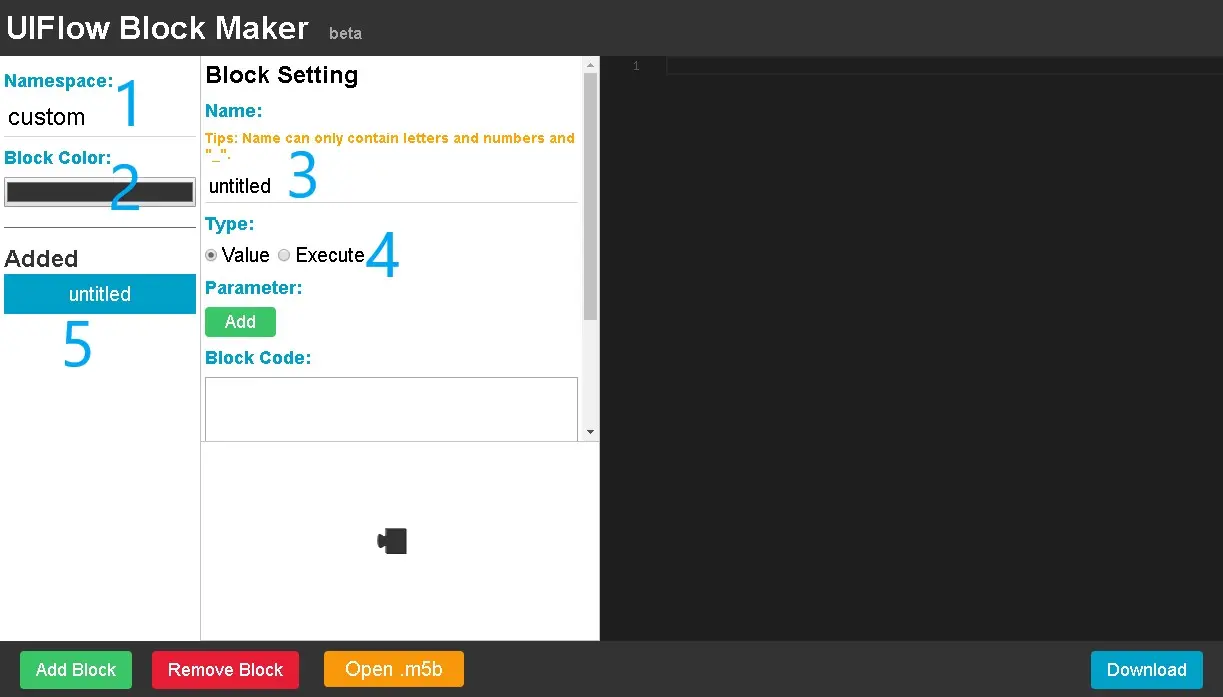
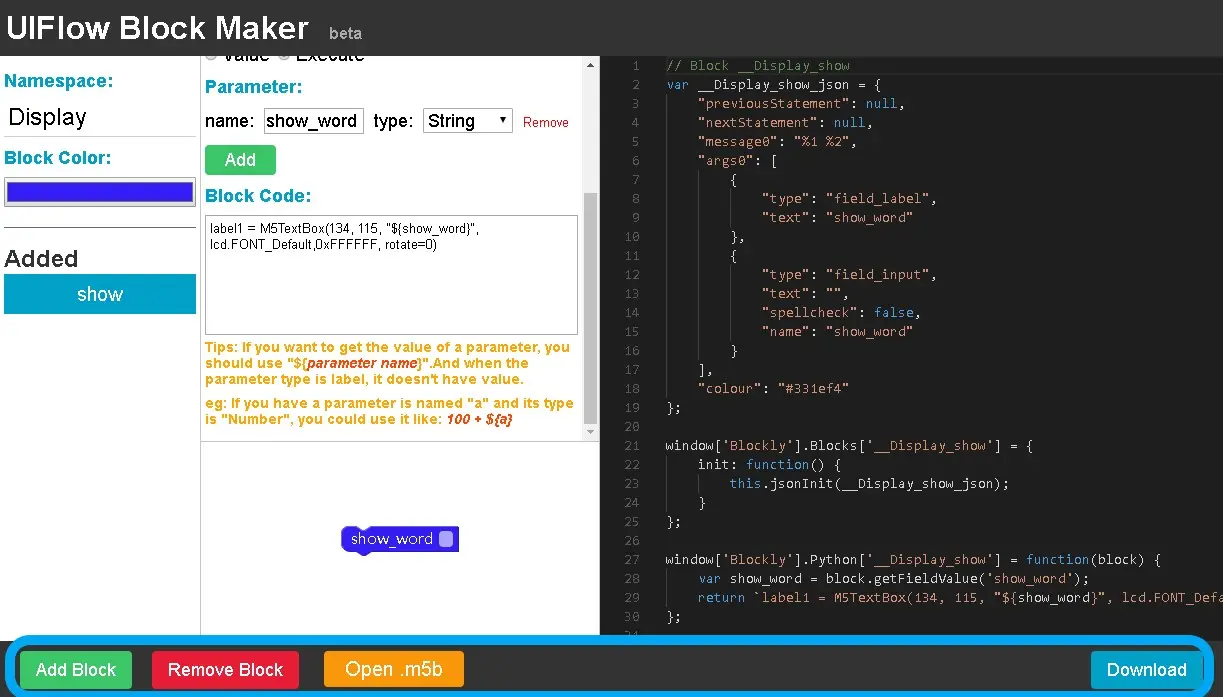
Haga clic en la opción Agregar en Parámetro, agregue una propiedad del programa, ingrese el nombre que se muestra en el bloque y seleccione el tipo de propiedad. Ingrese el código contenido en el bloque personalizado en el cuadro de opción Código de bloque.
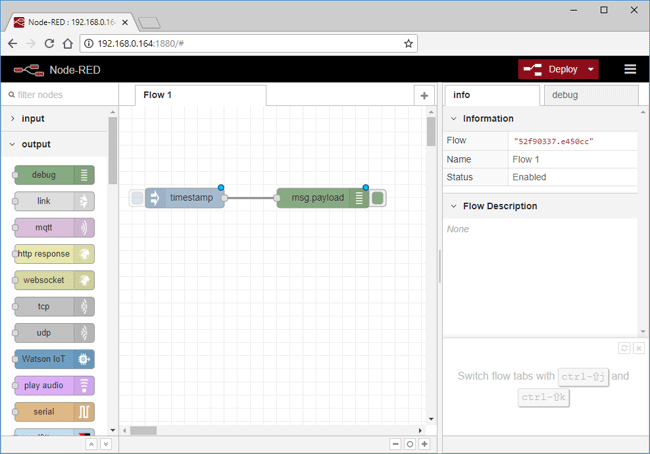
Node-RED es un motor de flujos con enfoque IoT, que permite definir gráficamente flujos de servicios, a través de protocolos estándares como REST, MQTT, Websocket, AMQP… ademas de ofrecer integración con apis de terceros, tales como Twitter, Facebook, Yahoo!…
Nodo: Un nodo es el bloque de construcción básico de un flujo. Los nodos se activan al recibir un mensaje del nodo anterior en un flujo o al esperar algún evento externo, como una solicitud HTTP entrante, un temporizador o un cambio de hardware GPIO. Procesan ese mensaje o evento y luego pueden enviar un mensaje a los siguientes nodos del flujo.
Nodo de Configuración: Un nodo de configuración (config) es un tipo especial de nodo que contiene una configuración reutilizable que los nodos regulares pueden compartir en un flujo.
Flow (Flujo) Un flujo se representa como una pestaña dentro del espacio de trabajo del editor y es la forma principal de organizar los nodos. El término «flujo» también se utiliza para describir informalmente un conjunto único de nodos conectados. Por lo tanto, un flujo (pestaña) puede contener múltiples flujos (conjuntos de nodos conectados).
Contexto: El contexto es una forma de almacenar información que se puede compartir entre nodos sin usar los mensajes que pasan a través de un flujo. Hay tres tipos de contexto:
Nodo: solo visible para el nodo que establece el valor
Flujo: visible para todos los nodos en el mismo flujo (o pestaña en el editor)
Global: visible para todos los nodos
Mensaje: Los mensajes son los que pasan entre los nodos en un flujo. Son objetos simples de JavaScript que pueden tener cualquier conjunto de propiedades. A menudo se les conoce como msg dentro del editor. Por convención, tienen una propiedad llamada “payload” que contiene la información más útil.
Subflow: Un subflujo es una colección de nodos que se contraen en un solo nodo en el espacio de trabajo. Se pueden usar para reducir la complejidad visual de un flujo o para agrupar un grupo de nodos como un componente reutilizable que se usa en varios lugares.
Wire: Los cables conectan los nodos y representan cómo pasan los mensajes a través del flujo.
Palette (Paleta): La paleta está a la izquierda del editor y enumera los nodos que están disponibles para usar en los flujos. Se pueden instalar nodos adicionales en la paleta utilizando la línea de comandos o el Administrador de paletas.
Workspace: El área de trabajo es el área principal donde se desarrollan los flujos arrastrando nodos de la paleta y conectándolos. El espacio de trabajo tiene una fila de pestañas en la parte superior; uno para cada flujo y cualquier subflujo que se haya abierto.
Barra Lateral: La barra lateral contiene paneles que proporcionan una serie de herramientas útiles dentro del editor. Estos incluyen paneles para ver más información y ayuda sobre un nodo, para ver el mensaje de depuración y para ver los nodos de configuración del flujo.
Con respecto a Node-RED, se pueden hacer muchas cosas. Desde encender un LED en remoto, crear una API Rest en 5 minutos o conectar con una base de datos InfluxDB para graficar con Grafana. Aunque es visual, se requieren unos conocimientos técnicos en programación y tecnología medios y/o avanzados.
También permite programar en JavaScript funciones que pueden hacer de todo. Node-RED da mucho juego para muchas cosas.
El editor de flujos de Node-RED consiste en una sencilla interfaz en HTML, accesible desde cualquier navegador, en la que arrastrando y conectando nodos entre sí, es posible definir un flujo que ofrezca un servicio.
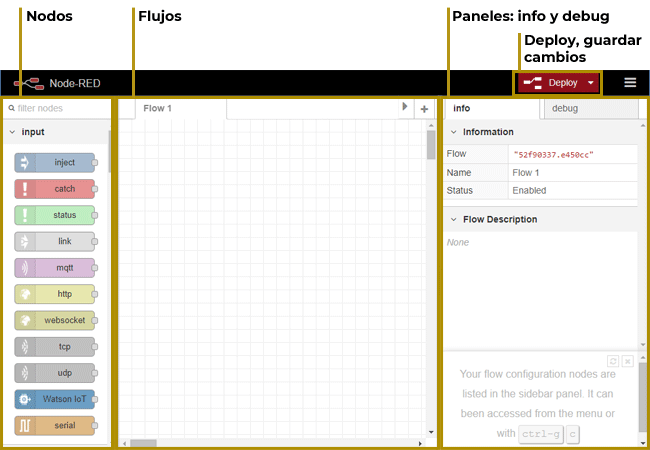
Como vemos, el editor se estructura como un entorno gráfico sencillo con:
Paleta de Nodos: Muestra todos los nodos que tenemos disponibles en nuestra instalación. Como veremos más adelante, existe un repositorio de nodos desarrollados por otros usuarios e incluso podemos crear e instalar nuestros propios nodos.
Editor: Nos permite arrastrar nodos desde la paleta y conectarlos. De este modo iremos creado el flujo de operación. El lienzo de node-red no tiene límites y se puede hacer zoom.
Asimismo, seleccionando cada nodo, se muestra a la izquierda su formulario de configuración, donde es posible establecer las propiedades concretas de dicho nodo:
En node-Red los nodos se comunican entre sí mediante msg, que es un objeto con propiedades y que podemos añadir propiedades. La propiedad principal es payload, pero puedo añadir las que quiera. Puedo añadir otras propiedades como temperatura.
Los nodos se unen en flujos que se ejecutan en paralelo.
En los nodos con entrada y salida, lo que entra sale y se mantiene la información salvo la que modifiques en el nodo.
Hay tres propiedades principales y que siempre existen:
Disponemos de un debug que nos muestra el objeto y la podemos sacar por pantalla.
Los nodos son la unidad mínima que podemos encontrar en Node-RED. En la parte izquierda de la interfaz podemos ver la lista de nodos que vienen instalados por defecto y organizados en categorías según su funcionalidad.
Hay nodos de entrada, salida, funciones, social, para almacenar datos, etc… Esto muestra la capacidad de Node-RED de comunicarse con otros servicios.
Se pueden clasificar en tres tipos de nodos:
Nodos que sólo admiten entradas: sólo admiten datos de entrada para ser enviados a algún sitio como pueda ser una base de datos o un panel de control.
Nodos que sólo admiten salidas: son los nodos que sólo ofrecen datos tras recibirlos a través de diferentes métodos como por ejemplo un mensaje MQTT.
Nodos que admiten entradas y salidas: estos nodos nos permiten la entrada de datos y luego ofrecen una o varias salidas. Por ejemplo, podemos leer una temperatura, transformarla en grados Celsius y enviarla a otro nodo.
Los nodos los arrastramos al flujo o flow, en inglés. Aquí es donde tendremos la lógica para cada dato a base de ir arrastrando nodos.
Existen además muchos tipos de nodos que podemos ver en https://flows.nodered.org/ que son contribuciones de terceros.
Los nodos se organizan en flujos, para organizar los nodos como queramos. Es recomendable agrupar en flujos tareas que tengan relación entre ellos, pero solo a modo organizativo.
Python es un lenguaje interpretado, es decir, no requiere del proceso de escribir / compilar / volcar. Simplemente escribir la instrucción y listo el ordenador la “interpreta” o sea ejecuta sobre la marcha sin más complicación.
Esto hace que los lenguajes interpretados sean más fáciles de aprender porque nos parecen más naturales, y aunque el programa corre más lento que en los compilados, pero con la potencia actual o es tan importante.
Python no es un lenguaje diseñado para ser fácil comprometiendo su potencia. Muy al contrario la potencia y capacidad de cálculo que muestra suelen sorprender a la gente acostumbrada a otros lenguajes.
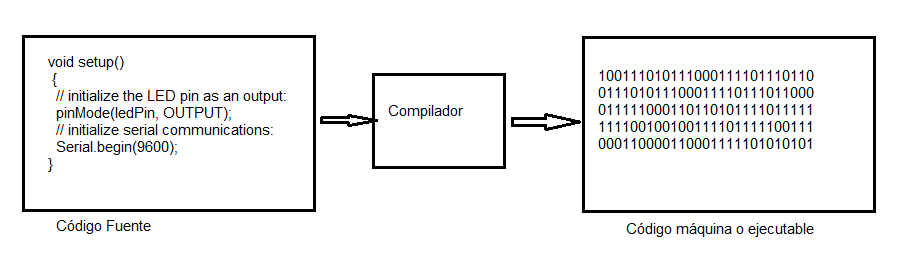
Para quienes vengáis de Arduino, C++ es un lenguaje compilado, esto significa que el compilador lee lo escrito en una primera pasada y después compila, es decir traduce a un lenguaje propio del micro de Arduino qué es lo que se vuelca y ejecuta la placa que usemos.
Hay dos versiones de Python 2 y 3, pero la versión 2 ya no tienes soporte desde el 1 de enero de 2020, aunque en Raspbian disponemos de las dos versiones. El inconveniente es que hay librerías que aún se mantienen en Python 2.
Para iniciar python se puede hacer desde consola:
python
python3
O usar el entorno gráfico con IDLE. IDLE significa Integrated DeveLopment Environment, o Integrated Development and Learning Environment.
Para instalarlo ejecutar: sudo apt-get install idle3
Dentro de la consola ya es posible ejecutar comandos.
Otra opción es usar el Thonny Python IDE incluido en Raspbian: https://thonny.org/
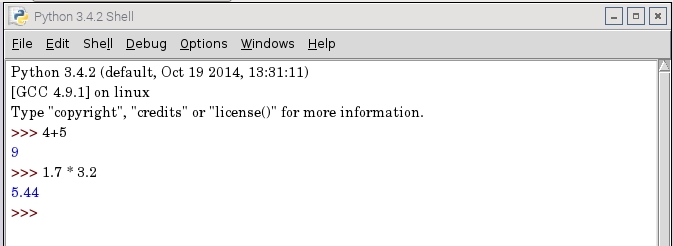
Práctica: Ejecutar los comandos:
3.8 + 7
2 * (3+5) / 4
“Hola.”
x=3
H=»Buenos dias»
print(x)
print(h)
print(H)
print(x,H)
123 ** 1234
Python puede con grandes números mientras le quede memoria RAM, pero tu Raspberry puede quedarse un tanto bloqueada mientras calcula.
El resumen es que Python tiene una precisión ilimitadamente grande en los enteros mientras tenga recursos disponibles, un detalle sorprendente para cualquiera que este acostumbrado a programar en otros lenguajes, y una de las razones por las que Python se ha convertido en lenguaje de facto para la ciencia y especialmente para la investigaciones numéricas.
Práctica: crear un fichero llamado hello.py que saque por pantalla el texto “Hola Mundo” desde consola conectado por ssh y ejecutarlo.
Una variable es algo parecido a un contenedor o cajón con un nombre. Una cosa es el nombre del cajón y otra su contenido y conviene entender desde ya la diferencia.
Las variables pueden tomar distintos valores e ir cambiandolo en función del programa, de la misma manera que un cajón puede ir variando su contenido sin que se mueva de sitio.
En Python no es necesario definir las variables antes de usarlas, a diferencia de C y similares. Basta con que la declares asignándole un valor.
Por ejemplo escribe directamente:
base = 86
iva = base * 0.21
total = base + iva
print (total)
print(base, iva, total)
base = input («Dame el precio del artículo, por favor : «)
print(base + base * 0.21)
type(base)
print (int(base) + int(base) * 0.21)
iva = float(base) * 0.21
print (int(base) +iva)
Práctica: Hacer un programa llamado iva.py y que pida el valor del articulo y devuelva el valor con iva.
En Python existen 4 tipos diferentes de variables numéricas:
int Número entero con precisión fija (ℤ).
long Número entero en caso de sobrepasar el tamaño de un int.
float Número en coma flotante de doble precisión (ℝ).
complex Número complejo (parte real + j parte imaginaria) (ℂ)
Una función muy útil, que sirve para conocer el tipo de una variable es: type()
El tipo booleano es un tipo de variable que sólo puede contener dos valores: True y False.
Se definen como caracteres entre comillas simples ‘ o dobles «.
Tipo listas
Se definen poniendo el contenido de la lista entre corchetes, separando cada uno de los elementos mediante una coma. Cada posición de la lista puede contener elementos de distinto tipo. Además, las listas son mutables, es decir, sus elementos pueden ser modificados. En Python los elementos de una lista se numeran desde 0 hasta longitud−1.Hay numerosas funciones que pueden aplicarse a una lista.
Para acceder al elemento de una lista se pone el nombre de la lista y a continuación el índice al que queremos acceder entre corchetes(si ponemos el índice con signo negativo empezará por el final de la lista). Para acceder a un rango dentro de una lista tenemos diferentes opciones:
Desde el inicio tomar a elementos (no incluye a): lista[:a]
Desde la posición a (incluida) tomar todos los elementos hasta el final lista[a:]
Tomar los elementos desde a hasta b (sin incluir b) lista[a:b]
Las listas tienen asociadas una serie de métodos que permiten una gran variedad de operaciones sobre ellas:
.append(), añade un elemento al final de la lista.
.insert(), se usa para insertar un elemento en el índice asignado.
.pop(), elimina y devuelve el valor en la posición del índice asignado.
Las tuplas son similares a las listas, se definen con paréntesis en vez de corchetes. Tienen la peculiaridad de ser inmutables.
Tipo diccionarios
Los diccionarios definen una relación uno a uno entre claves y valores y son mutables. Se definen colocando una lista separada por comas de pares clave:valor. Una vez definido, podemos acceder al valor asociado a una clave buscando por la clave. Además, podemos buscar si una determinada clave existe o no en nuestro diccionario.
Los diccionarios se definen con {}
.keys()
.values()
.items() – devuelve una lista de tuplas clave – valor del diccionario
zip me permite coger dos listas y hacer un diccionario: diccionario = dict(zip(lista_claves,lista_valores))
del(diccionario[‘clave’]) – borra la entrada de un diccionario
Ojo, al copiar un diccionario con ciudades_2 = ciudades, no creo una copia sino dos variables que apuntan a un mismo objeto.
id(diccionario) – me devuelve el número del puntero al diccionario
ciudades_2 = ciudades.copy() -> así tengo una copia independiente de un diccionario
Las diferentes operaciones aritméticas en Python son los siguientes:
+
−
∗
∗∗ – elevado
/ – división entera
// – división
%
Operadores de asignación
Los diferentes operadores de asignación en Python son los siguientes:
=: Asigna a la variable del lado derecho aquello que pongamos en el lado derecho.
+=: Suma a la variable del lado izquierdo la variable del lado derecho.
−=: Resta a la variable del lado izquierdo la variable del lado derecho.
∗=: Multiplica la variable del lado izquierdo por la variable del lado derecho.
/=: Divide la variable del lado izquierdo por la variable del lado derecho.
∗∗=: Eleva la variable de la izquierda a la potencia de la variable de la derecha.
//=: División entera de la variable de la izquierda entre la de la derecha.
%=: Resto de la división de la variable de la izquierda entre la de la derecha.
Operadores relacionales
Los operadores relacionales de Python son:
==: Evalúa que los valores sean iguales.
!=: Evalúa que los valores sean distintos.
<: Evalúa que el valor de la izquierda sea menor que el de la derecha.
>: Evalúa que el valor de la izquierda sea mayor que el de la derecha.
<=: Evalúa que el valor de la izquierda sea menor o igual que el de la derecha.
>=: Evalúa que el valor de la izquierda sea mayor o igual que el de la derecha.
not: negación de una variable booleana
Librerías
Python es un lenguaje pensado para ser ampliado con lo necesario y hace tiempo que se ha convertido en el pilar de la investigación en numerosos campos de ciencia y tecnología
Disponemos de infinidad de librerías que podemos usar llamando a la clausula import
NumPy es una extensión de Python, que le agrega mayor soporte para vectores y matrices, constituyendo una biblioteca de funciones matemáticas de alto nivel para operar con esos vectores o matrices.
Estos módulos externos que podemos descargar e importar a nuestros programas reciben en Python el nombre de packages. Existen packages que podemos importar, más o menos estándar para lo que se te ocurra.
El Python Package Index o PyPI es el repositorio de software oficial para aplicaciones de terceros en el lenguaje de programación Python. Los desarrolladores de Python pretenden que sea un catálogo exhaustivo de todos los paquetes de Python escritos en código abierto. https://es.wikipedia.org/wiki/%C3%8Dndice_de_paquetes_de_Python
Para ver la ruta de los paquetes:
import sys
print (‘\n’.join(sys.path))
Para ver los módulos instalados: pip freeze o pip list
Para actualizar ejecutar: pip install –upgrade pip
Imaginemos que queremos crear un sistema automático de riego en nuestra casa, de forma que cuando la lectura de un sensor de humedad sea menor que un cierto valor, encienda el sistema y que si la lectura es mayor que un cierto valor, lo apague. Con las herramientas que tenemos hasta ahora, esto no sería posible, para esto utilizamos la sentencia if/elif/else, que tiene la siguiente estructura:
if <expresion_booleana>: # Solo si la condicion booleana es True,
bloque codigo # el bloque de código se ejecuta
…
elif <expresion_booleana>: # No es necesario, añade condiciones extra al conjunto.
bloque codigo # Se puede poner tantas como se necesiten.
…
else: # No se necesario. Se ejecuta solo si
bloque codigo # todas las condiciones anteriores son falsas.
…
Nota: Es importante saber la importancia de la indentación en Python. Cuando usemos sentencias que acaben en «:» (if, for…) las líneas que estén dentro de esta sentencia irán después de un tabulador o 4 espacio, como se muestra en los ejemplos.
Anteriormente hemos visto el tipo de variable lista. Estas contenían una cierta cantidad de elementos. Imaginemos que tenemos una lista de enteros y queremos mostrar por pantalla los elementos que contiene que sean mayores que 5. Para esto, entre otras cosas, tenemos sentencias bucle.
En Python existen dos tipos estructuras de bucles:
Bucles for
Bucles while
La sintaxis de un bucle for es:
for <variable_sin_definir> in <Iterable>: # El bloque se ejecuta tantas veces
bloque codigo # como elementos tiene el iterable
…
El blucle ejecuta un bloque de código tantas veces como esté definido. El número de veces que se recorre el bucle es equivalente al número de elementos en el iterable que se usa. La variable que se usa toma como valores los elementos del iterable de forma secuencial, un valor por cada iteración.
Los bucles for son una gran herramienta para recorrer todos los elementos de una colección.
Ejemplo:
fruits = [«apple», «banana», «cherry»]
for x in fruits:
print(x)
Ejemplo:
for x in range(6):
print(x)
else:
print(«Finally finished!»)
La sintaxis de los bucles while es:
while <condicion_boolena>: # El bloque se ejecuta hasta que la condición es falsa.
bloque codigo # Antes de ejecutar asegurarse que se va a salir.
…
El bucle while se ejecuta de forma indefinida hasta que la condición después del while sea falsa. Por lo tanto es necesario realizar un cambio dentro del bucle que finalmente hará que se vuelva la condición False.
Adicionalmente existen un par de comandos dentro de Python que sirven para tener más control sobre los bucles:
continue. El intérprete cuando lo lee termina de ejecutar la presente iteración y pasa a la siguiente iteración.
break . El intérprete cuando lo lee termina la ejecución del bucle, continuando la ejecución de las siguientes líneas.
En Python existen diferentes estructuras que son conjuntos de elementos, son las llamadas colecciones. Este tipo de estructuras son iterables, es decir, se pueden recorrer elemento por elemento. Como veíamos antes, el bucle for itera sobre un iterable, por lo que utilizamos esta sentencia para recorrerlos. Algunos tipos de variable que son iterables son:
Cadena de caracteres (str)
Lista (list)
Tupla (tuple)
Diccionario (dict)
Además, muchas veces queremos repetir un bucle un número determinado de veces. Para esto puede ser útil la función range(n). Esta función genera un iterable que va desde 0 hasta n-1.
Es muy posible que a lo largo de un programa necesitemos calcular el factorial de un número. Podemos escribir el código necesario para calcularlo en cada punto que lo necesitamos, o crear una función que podamos llamar desde cualquier punto y nos calcule el factorial de un número.
La sintaxis para definir una función en Python es la siguiente:
def nombre_funcion(<parametro1>, <parametro2>, …): # Los parametros son opcionales
Bloque codigo
…
return <valor_a_devolver> # El comando es opcional (puede devolver varios valores)
Los parámetros son las variables que se definen dentro del paréntesis, separados por comas. Son opcionales y sirven para pasarle valores a la función. Son opcionales una vez definimos la función, pero si la función está definida con n argumentos, tendremos que informarlos.
Adicionalmente puede introducirse una sentencia return que termina la ejecución de la función y devuelve el valor/objeto que está colocado justo después.
Los nombres de las funciones sigue el mismo convenio que el de las variables.
Para llamar a una función, como hemos visto antes, tenemos que escribir el nombre de la función y añadir entre paréntesis los argumentos que la funció necesita. Aunque la función no necesite argumentos, tenemos que escribir los paréntesis.